Bounding Mixing Times of Markov Chains via the Spectral Gap

A Markov chain that is aperiodic and irreducible will eventually converge to a stationary distribution. This is widely used in many applications in machine learning, such as in Markov Chain Monte Carlo (MCMC) methods, where random walks on Markov chains are used to obtain a good estimate of the log likelihood of the partition function of a model, which is hard to compute directly as it is #P-hard (this is even harder than NP-hard). However, one major issue is that it is unclear how many steps we should take before we are guaranteed that the Markov chain has converged to the true stationary distribution. In this post, we will see how the spectral gap of the transition matrix of the Markov Chain relates to its mixing time.
Mixing Times
Our goal is to try to develop methods to understand how long it takes to approximate the stationary distribution $\pi$ of a Markov Chain. Our goal is to eventually show that the mixing time is in $O\left(\frac{\log (n)}{1 - \beta}\right)$, where $\beta$ is the second largest eigenvalue of the transition matrix of the Markov Chain.
Aside: Coupling
Coupling is one general technique that allows us to bound how long it takes for a Markov Chain to converge to its stationary distribution based. It is based on having two copies of the original Markov Chain running simultaneously, with one being at stationarity, and showing how they can be made to coincide (i.e have bounded variation distance) after some time (known as the coupling time).
We will not discuss coupling in this post, but will instead develop how spectral gaps can be used, as this is more useful for other concepts.
The Spectral Gap Method
The main idea of the Spectral Gap method is that the mixing time is bounded by the inverse of the spectral gap, which is the difference between the largest and second largest eigenvalues of the transition matrix.
Before we can talk about one distribution approximating another, we need to first introduce what closeness between two distributions means The formulation that we will use is via the Total Variation Distance.
The equality between the two lines can be observed from the fact that
\[\begin{align} \max_{A \subseteq \Omega} \sum\limits_{\omega \in A} \mathcal{D}_1(\omega) - \sum\limits_{\omega \in A} \mathcal{D}_2(\omega)= \max_{B \subseteq \Omega} \sum\limits_{\omega \in B} \mathcal{D}_2(\omega) - \sum\limits_{\omega \in B} \mathcal{D}_1(\omega), \end{align}\]since both $\mathcal{D}_1, \mathcal{D}_2$ are probability distributions and integrate to 1. See Figure 1 for an illustration.
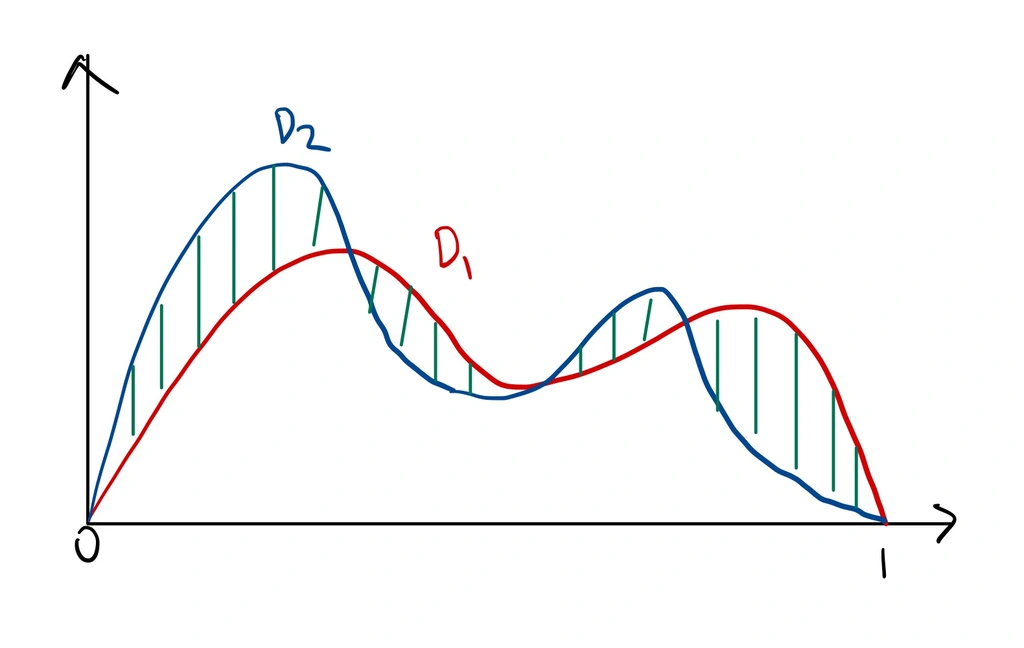
Intuition for Mixing Times
We consider how long it takes to converge on some special graphs to build up intuition.
Random Walks on Path Graphs
The path graph is a line graph on $n$ vertices. We claim that the mixing time of the path graph is at least $n$: this is because it takes at least $n$ steps to even reach the rightmost vertex from the leftmost vertex.

Random Walks on the Complete Graph
The complete graph $K_n$ on $n$ vertices is one where each vertex has an edge to every other vertex.
This only takes 1 step to mix, since after a single step we can reach any vertex.
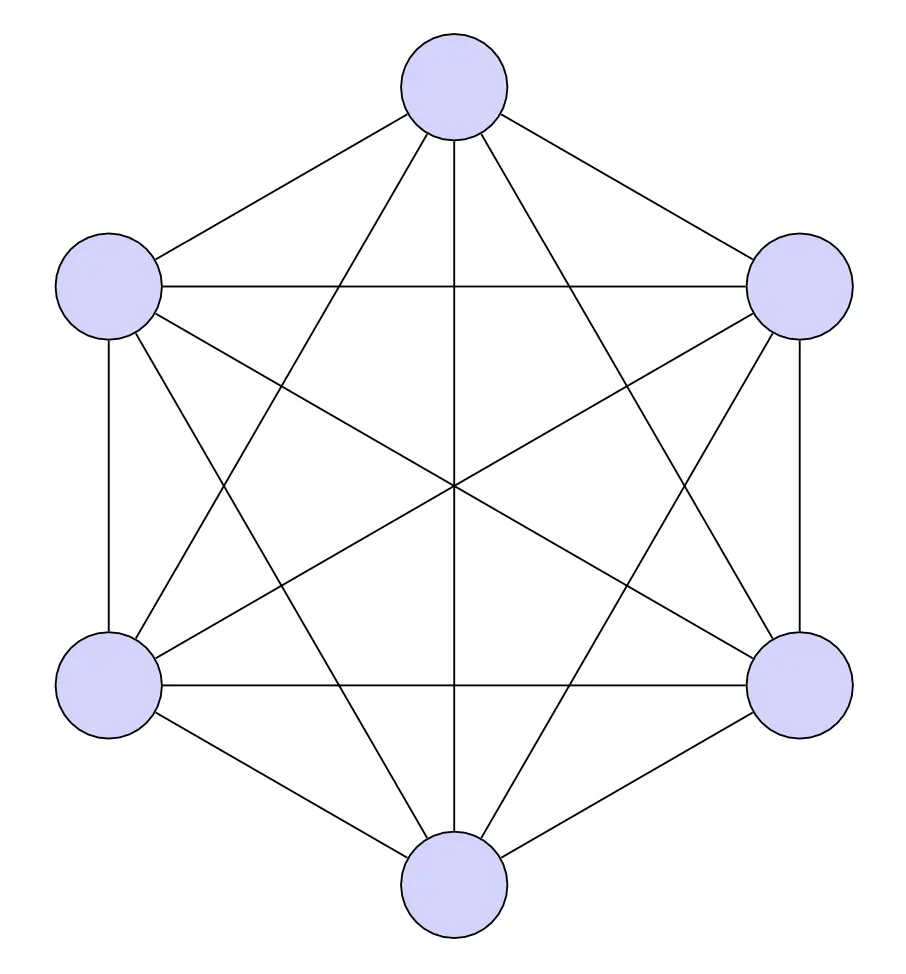
This short analysis tells us that if our graph looks like a line graph then we should expect poor mixing times; whereas if it looks more like a complete graph then we can expect the opposite.
\[\newcommand{\tmix}{\tau_{\mathsf{mix}}} \newcommand{\sgap}[1]{\mathsf{spectral\_gap}(#1)}\]Mixing Times
We now formally introduce the concept of mixing times.
We claim that the choice of $\frac{1}{4}$ in defining $\tmix$ does not matter.
To bound mixing times, we consider random walks on undirected, regular graphs $G$. The same analysis can be extended to directed, weighted, irregular graphs, but it causes the notation to become more cumbersome and distracts from the key ideas.
Consider random walks on an undirected, regular graph $G(V, E)$, $|V| = n$. Define the transition matrix $T$ of the graph to be
\[\begin{align} T_{ij} = \begin{cases} \frac{1}{\deg(j)} & \text{if $j \sim i$} \\ 0 & \text{otherwise} \end{cases} \end{align}\]where $j \sim i$ means that $j$ shares an edge with $i$.
The stationary distribution for $T$ is given by
\[\begin{align} \pi = \left( \frac{\deg (1)}{2|E|} , \dots, \frac{\deg (n)}{2|E|} \right). \end{align}\]This can be seen from the following:
\[\begin{align} (T \pi)_i & = \sum\limits_{j \in [n]} \frac{\deg (j)}{2 |E| } \mathbb{1} \begin{rcases} \begin{dcases} \frac{1}{\deg(j)} & \text{ if $j \sim i$}, \\ 0 & \text{ otherwise. } \\ \end{dcases} \end{rcases} \\ & = \sum\limits_{j \sim i} \frac{\deg(j)}{2 |E| } \frac{1}{\deg (j)} \\ & = \frac{ \deg (i) }{2|E|}. \end{align}\]If $G$ is $d$-regular, then
\[\begin{align} T = \frac{1}{d} \cdot A, \end{align}\]where $A$ is the adjacency matrix of the graph.
Spectral Graph Theory
Spectral graph theory is the study of how the eigenvalues and eigenvectors of the matrix of a graph reveals certain properties about the graph, for instance, how well-connected it is.
- $|\lambda_i| \leq 1$ for all $i$, and $\lambda_1 = 1$
- $\lambda_2 < 1$ if and only if $G$ is connected
- $\lambda_n > -1$ if and only if $G$ does not have a bipartite connected component
We prove each of the claims in Lemma 1 in order.
Let $v_i$ be the maximum magnitude entry of $v$. Observe that $v$ is an eigenvector of $T$ only if $Tv = \lambda v$ for some $\lambda$. Then \begin{align} \lambda v_i \label{eq:max_entry} & = (Tv)_i \\ & = \sum\limits_{j \in N(i)} \frac{1}{d} \cdot v_j & \text{(Multiplying $i$th row of $T$ by $v$)} \\ & \leq | v_i | \end{align} The last step comes from the fact that since each $|v_j| \leq |v_i|$, so at most we have $d \times \frac{1}{d}|v_i| = |v_i|$, recalling that $|N(i)| = d$ since the graph is $d$-regular.
This shows that $|\lambda v_i| \leq |v_i|$ for all $i$, and so $|\lambda| \leq 1$.
It remains to show that $\lambda_1=1$. To see this, consider the vectors where all entries are 1, i.e $\mathbb{1}$. Then $T \cdot \mathbb{1} = \mathbb{1}$. So $\mathbb{1}$ is an eigenvector of $T$ with eigenvalue 1.
WLOG, assume that the graph has two distinct connected components; the proof easily extends to having more components.
Let $S_1, S_2$ be connected components of $G$. Recall that the connected components of $G$ are the equivalence class of components where in each component, all vertices are reachable from any other vertex.
Define $v^1, v^2$ via \begin{align*} v^1_i = \begin{cases} 1 & \text{if $i \in S_1$,} \\ 0 & \text{otherwise,} \\ \end{cases} \\ v^2_i = \begin{cases} 1 & \text{if $i \in S_2$,} \\ 0 & \text{otherwise.} \\ \end{cases} \\ \end{align*}
Then \begin{align} (T \cdot v^1)_i & = \sum\limits_{j \in N(i)} \frac{1}{d} v^1_j & \text{(multiplying row $i$ of $T$ by $v^1$)} \\ & = \sum\limits_{j \in N(i)} \frac{1}{d} \mathbb{1} \left\{ j \in S_1 \right\} \\ & = \begin{cases} 1 & \text{if $i \in S_1$,} \\ 0 & \text{otherwise.} \\ \end{cases} \end{align} This shows that $T \cdot v^1 = v^1$. Similarly, we can perform the same sequence of steps to derive that $T \cdot v^2 = v^2$.
We can show the same for $v^2$ to get $T \cdot v^2 = v^2$. which shows that $\lambda_2 = 1$.
Since by our disconnected assumption $v^1, v^2 \neq \mathbb{1}$, the all-ones eigenvector corresponding to eigenvalue $\lambda_1$, it means $\lambda_2 = 1$.
This shows the backwards direction.
$(\implies)$ For the other direction, suppose that $G$ is connected, we want to show that $\lambda_2 < 1$.
We will show that for any eigenvector $v$ with eigenvalue $1$, then it must be a scaling of $\mathbb{1}$.
Let $v$ be any eigenvector with eigenvalue $1$. Then let $v_i$ be its maximum entry. From Equation \ref{eq:max_entry}, we must have that \begin{align} \lambda v_i & = v_i \\ & = (Tv)_i \\ & = \sum\limits_{j \in N(i)} \frac{1}{d} \cdot v_j \\ & = v_i. \end{align} But since $v_i$ is the largest entry, it must be the case that $v_j = v_i$ for all $j \sim i$. We then repeat this argument to observe that all the neighbors of each $j$ must also take on the same value. Since the graph is connected, $v$ is just the uniform vector, as desired.
Note that this lemma shows that if $G$ is disconnected, then it has a spectral gap of 0.
Suppose that $G$ has a bipartite component $S$. We want to show that $\lambda_n = -1$.
Let $S = L \cup R$ denote the two disjoint bipartite components.
Define vector \begin{align} v_i = \begin{cases} 1 & \text{if $i \in L$,} \\ -1 & \text{if $i \in R$,} \\ 0 & \text{otherwise.} \\ \end{cases} \end{align} Again we compute $T \cdot v$, and consider its $i$th entry: \begin{align} \left( T \cdot v \right)_i & = \sum\limits_{j \in N(i)} \frac{1}{d} v_j \\ & = -v_i, \end{align} since the signs of its neighbors $N(i)$ are always the opposite of the sign of $v_i$ by construction.
Since $Tv = -v$, this shows that we have an eigenvector with eigenvalue $-1$.
$(\Longleftarrow)$ Now suppose that $Tv = -v$, with the goal to show that the graph is bipartite.
Similarly as for the backwards direction of Claim 2, we can see that this can only hold on each element $v_i$ if all the signs of the neighbors of $v_i$ have the same magnitude but opposite sign of $v_i$. Then we can similarly expand this argument to the neighbors of its neighbors, which shows that the graph is bipartite.
This shows how we can gleam useful information about a graph just from its eigenvalues.
Recall how we previously showed that a unique stationary distribution exists if the graph is connected and not bipartite. Now we have another characterization of the same property, except in terms of the eigenvalues of its transition matrix:
Our goal now is to formulate a robust version of this corollary, where we can bound the mixing time of approaching the stationary distribution.
Bounding the Mixing Time via the Spectral Gap
We define the spectral gap:
We now finally introduce a lemma that shows that the mixing time is proportional to the inverse of the spectral gap multiplied by a log factor:
This shows that if your spectral gap is bounded by a constant, your mixing time is in $O(\log (n))$.
Proof
We now prove Lemma 2.
Let $T$ have eigenvalues $1 = \lambda_1 \geq \lambda_2 \geq \dots \geq \lambda_n$ with eigenvectors $v^1, v^2, \dots, v^n$. Assume that the eigenvectors are scaled to be unit vectors.
Since this is a symmetric matrix, the eigenvectors are pairwise orthogonal.
We can perform an eigenvalue decomposition of $T$ in terms of its eigenvectors via \begin{align}\label{eq:decomp} T = \sum\limits_i \lambda_i v_i v_i^\top . \end{align}
It follows from Equation \ref{eq:decomp} that \begin{align} T^k = \sum\limits_i \lambda_i^k v_i v_i^\top . \end{align}
Let $x \in [0,1]^n$ be a probability vector of $G$ where all entries are non-negative and sum to 1. Think of $x$ as the start state of the Markov chain.
After $k$ steps, the state will be $T^k \cdot x$.
We can re-write $x$ in terms of the orthogonal basis of the eigenvectors of $T$, i.e \begin{align} x = \sum\limits_{i} \langle x, v_i \rangle \cdot v_i. \end{align} Write $a_i = \langle x, v_i \rangle $ to be the coefficients of each eigenvector $v_i$.
$\lambda_1=1$, so $\lambda_1^k = 1$. We also know that
\[\begin{align} v^1 = \begin{pmatrix} \frac{1}{\sqrt{n}} \\ \vdots \\ \frac{1}{\sqrt{n}} \\ \end{pmatrix}, \end{align}\]since we previously showed that the all-ones vector is always an eigenvector with eigenvalue 1, where here it is re-scaled to have unit norm.
Then \(\begin{align} T^k \cdot x & = \sum\limits_{i} \langle x, v_i \rangle \cdot \lambda_i^k \cdot v_i \\ & = \langle x, v^1 \rangle \cdot v^1 + \sum\limits_{i \geq 2} \langle x, v_i \rangle \cdot \lambda_i^k \cdot v_i \\ & = \frac{1}{n} \langle x, \mathbb{1} \rangle \cdot \mathbb{1} + \sum\limits_{i \geq 2} \langle x, v_i \rangle \cdot \lambda_i^k \cdot v_i \\ & = \begin{pmatrix} \frac{1}{n} \\ \vdots \\ \frac{1}{n} \\ \end{pmatrix} + \sum\limits_{i \geq 2} \langle x, v_i \rangle \cdot \lambda_i^k \cdot v_i, \end{align}\)
where the last step follows from the fact that $x$ is a probability distribution and thus $x \cdot \mathbb{1} = 1$.
Rearranging and moving to work in the L2 (Euclidean) norm, we obtain
\[\begin{align} \left| \left| T^k \cdot x - \begin{pmatrix} \frac{1}{n} \\ \vdots \\ \frac{1}{n} \\ \end{pmatrix} \right| \right|_2 & = \left| \left| \sum\limits_{i = 2}^n \langle x, v_i \rangle \cdot \lambda_i^{k} v_i \right| \right|_2 \\ & = \sqrt{ \sum\limits_{i = 2}^n \langle x, v_i \rangle^2 \cdot \lambda_i^{2k} \cdot \| v_i \|^2_2 } \\ & \text{(def of L2 norm, x-terms cancel as e.v are pairwise orth)} \\ & = \sqrt{ \sum\limits_{i = 2}^n \langle x, v_i \rangle^2 \cdot \lambda_i^{2k} } \\ & \text{($v_i$ has unit norm)} \\ & \leq \| x \|_2 \cdot \beta^k, \end{align}\]where the last step comes from the fact that $\lambda_i \leq \beta$ for all $i \geq 2$ since $\beta$ is the second-largest eigenvalue, and $\sum\limits_{i = 1}^n \langle x, v_i \rangle^2 = | x |_2^2$ .
Since $| x |_2 \leq 1$, we can simplify
\[\begin{align} \left| \left| T^k \cdot x - \begin{pmatrix} \frac{1}{n} \\ \vdots \\ \frac{1}{n} \\ \end{pmatrix} \right| \right|_2 & \leq \beta^k \\ & = (1 - (1 - \beta))^k. \end{align}\]However, what we really care about is the total variation distance, which is the quantity
\[\begin{align} \frac{1}{2} \left| \left| T^k \cdot x - \begin{pmatrix} \frac{1}{n} \\ \vdots \\ \frac{1}{n} \\ \end{pmatrix} \right| \right|_{TV} \\ = \frac{1}{2} \left| \left| T^k \cdot x - \begin{pmatrix} \frac{1}{n} \\ \vdots \\ \frac{1}{n} \\ \end{pmatrix} \right| \right|_{1}. \end{align}\]Recall that for any $n$-dimensional vector $x$, $| x |_1 = \sqrt{n} | x |_s$ by Cauchy-Schwarz:
\[\begin{align} \| x \|_1 & = \mathbb{1} \cdot x \\ & \leq \| \mathbb{1} \|_2 \| x \|_2 \tag{by Cauchy-Schwarz} \\ & = \sqrt{n} \| x \|_2. \end{align}\]To relate the L2 distance to L1 distance, we can apply the above inequality to get \(\begin{align} \frac{1}{2} \left| \left| T^k \cdot x - \begin{pmatrix} \frac{1}{n} \\ \vdots \\ \frac{1}{n} \\ \end{pmatrix} \right| \right|_1 & \leq \frac{1}{2} \sqrt{n} \left| \left| T^k \cdot x - \begin{pmatrix} \frac{1}{n} \\ \vdots \\ \frac{1}{n} \\ \end{pmatrix} \right| \right|_2 \\ \\ & \leq \frac{1}{2} \sqrt{n} \beta^k \\ & \leq \frac{1}{4}, \tag{if $k > O\left( \frac{\log n}{1 - \beta} \right)$} \end{align}\) as desired.
So we set $k \geq O\left( \frac{\log n}{1 - \beta} \right)$ for the total variation distance to be less than 1/4.
We say that a Markov Chain is fast mixing if $\tmix \leq \log^{O(1)}(n)$.
Expander Graphs
Lemma 2 motivates the following definition of expander graphs:
From what we have learnt so far, we know that an expander has to be well-connected in order to have a large spectral gap. Expander graphs can be used for derandomization, which helps to reduce the amount of random bits required for algorithms.
Related Posts: