CMU 15-441/641 Computer Networks Course Review

Computer Networks is one of the lesser-known systems classes at Carnegie Mellon that turned out to be surprisingly fun and informative. In this post I’ll talk about the projects and content covered, followed by my own thoughts on the usefulness on the class and who should take it.
Projects
Project 1: A Web Server Called Liso
The first project involved writing a HTTP web server in C using the Berkeley Sockets API that serves content from a www directory, including dynamic CGI scripts. The implementation details were largely unspecified, we were instead directed to refer to the specifications for HTTP 1.1 outlined in RFC 2616 and to make our best judgment based on that. Given the finite length of the RFC but the infinite weird requests that users can come up to mess with your web server, a lot of care must be taken to guard against edge cases. This was the first time that I properly read an RFC, and I found it surprisingly well-organized.
You should take particular care to write code that is correct, modular, and readable, because a lot of your code in this project will be re-used in Project 3.
Project 2: TCP in the Wild
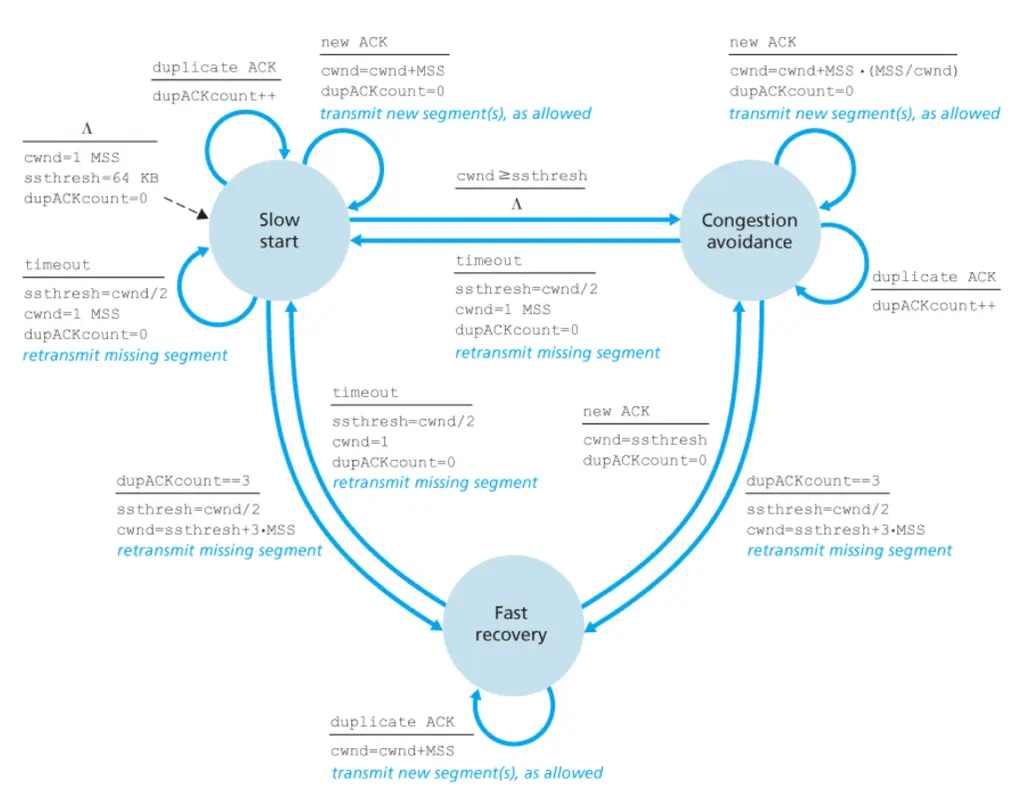
The second project was my favorite, and it involved implementing TCP on top of UDP with the Reno congestion control protocol together with a partner. This was followed by an analysis of how the protocol can be improved by performing data transfer between a client and server using our TCP stack, and then using tcpdump to perform packet capture and generate network I/O graphs. We performed close analysis on the TCP sawtooth patterns on these graphs, to come up with our own TCP congestion control protocol that has to non-trivially improve on both throughput and Jain’s Fairness Index (for fairness when multiple connections connect on the same link) as compared to TCP Reno.
Project 3: Video Delivery
The final project comprises two independent checkpoints: writing an adaptive bitrate proxy, and writing a load balancer. We had the option to only complete the adaptive bitrate proxy if we are working individually, or otherwise do both if we work in pairs. Almost everyone in the class opted to do just the first checkpoint solo. Since I had already written load balancers twice, once for 15-319 Cloud Computing and once for 15-440 Distributed Systems, I also chose to do the same.
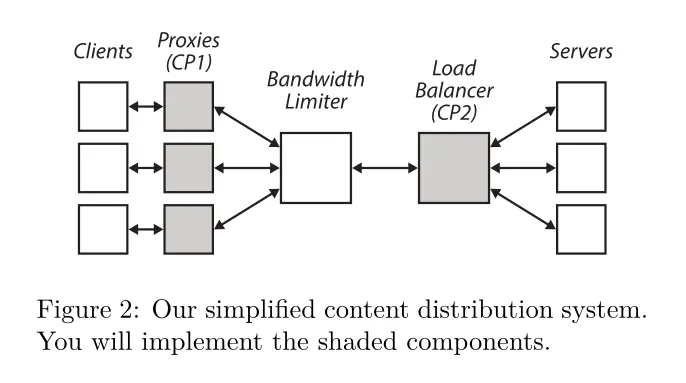
The relationship between the adaptive bitrate proxy and the load balancer is given in the graph above.
Checkpoint 1: Adaptive Bitrate Proxy
This is known as the “Netflix” project, where you have to write a web proxy for video streaming. You will most likely re-use a lot of your code from the web server you wrote in Project-1 to save time. Browsers will connect to your web proxy and request video chunks, and your proxy will dynamically adjust the bitrate of the video chunks sent to clients depending on their network conditions. This requires you to perform network throughput estimation with an exponentially weighted moving average for smoothing. Finally, you will also investigate how the proxy performs with multiple clients in terms of link utilization, fairness, and smoothness in a Docker environment with simulated network conditions.

You will probably watch Big Buck Bunny many many times while testing, which is the video that is used for streaming. The choice is because Big Buck Bunny is an open-source film from the Blender Foundation, ensuring that the course does not run into any copyright problems. I have to admit I was very impressed by the visuals and did not know that Blender was capable of such high-quality animation, based on my very limited experience with doing 3D modeling with it back in middle school.
I felt that this project was the simplest, as the design space is relatively constrained and there are not that many areas where you can go wrong. It was also a lot of fun to see your video proxy work for the first time and to see it change the quality of video streaming in real-time.
Checkpoint 2: Flow-Level Load Balancer
Note that I did not do this checkpoint, so whatever I say here is based on my interpretation of the write-up.
In this checkpoint, you will write a load balancer with two different load balancing algorithms. The load balancer will operate on the level of TCP flows.
The first algorithm uses consistent hashing, which has the advantage that even when the hash table gets resized (say when servers are removed or added), only \(n/m\) flows need to be remapped, where \(n\) is the number of flows and \(m\) is the number of servers. One limitation of this approach is that it may not distribute the actual load evenly, as some clients may request more data than others.
The second algorithm aims to address this shortcoming by being load-sensitive. This means that the load balancer must track the amount of load each server is currently servicing, and direct new TCP flows accordingly.
Finding a bug in the Project 2 Autograder
An interesting thing that happened during this project was that I found a race condition bug in the autograder for this project. When we went from the first checkpoint that checked for the implementation of the TCP three-way handshake and RTT estimation to the second checkpoint that required the implementation of the rest of the TCP state diagram, we began to fail a few very basic tests. The autograder claimed that we did not complete a TCP handshakes after a SYN packet was sent by the client. This completely puzzled me as our TCP implementation was able to complete the handshakes on many of the other occasions and proceed with multiple file transfers followed by teardown, and we should not have any regressions from the first checkpoint. I performed a lot of manual testing with scapy and Wireshark, and could not see that we were doing anything wrong.
Eventually, as I have already been debugging non-stop for 4 days and the TAs also could not identify any issues, I wrote a reverse shell out of exasperation to check the grading scripts, which ran when my code was being executed by the autograder. It turns out that the grading harness executes the grading client and causes it to send the initiation SYN packet via UDP on the wire immediately after the server subprocess is started. As such, if the packet gets sent before the server has managed to bind, it will be lost (our goal is to write a reliable transmission protocol, after all!). We were particularly susceptible to triggering this race because we performed a non-trivial amount of metadata setup before bind, which involved numerous memory allocation calls and memset’s that would have likely generated expensive page faults. Re-ordering these operations made the problems go away, but I also made sure to let the course staff know about the issue. This incident made me realize that course infrastructure can have problems too, so don’t always assume it’s your fault (although it probably is most of the time).
Course Content
All the lecture slides are posted online, so you can get a pretty good idea of what is covered from the course schedule page.
The areas that I had no idea about before taking this course were inter-domain routing (autonomous services, BGP), video streaming protocols and techniques, datacenter networks and network function virtualization, and how WiFi and mobile cellular networks work. I was genuinely surprised at how many blind spots I had in this regard as I have already taken quite a fair amount of systems classes by then. For the other topics, I had some exposure from day-to-day Linux usage and debugging network issues, CTF problems, and internship experience, but the lectures helped to deepen my understanding and reinforce my existing knowledge significantly.
My Thoughts
I felt that this course was very different from any of the other systems classes that I have taken, which usually swing between either being very micro-level such as OS (15-410) where a lot of emphases is on concurrency and the things happening at the hardware/software interface, or macro-level such as Distributed Systems (15-440) where you care about things like distributed cache consistency and permissionless distributed consensus protocols.
On the other hand, in Computer Networks you are thrust into the bizarre situation of having to contend with algorithms and protocols that evolved from many wildly different considerations. In fact, the professor once mentioned that if you want to talk to someone who is an expert in routing or shortest path graph problems, don’t go to the mathematics department, but come talk to a computer networks researcher.
First, you have the usual culprit of historical short-sightedness (or shall we say, the disappointing lack of ability to predict the future). For instance, IPv4 used to be a very complicated protocol that was designed to be extensible. But then many years later people realized that they wanted things to be fast, and for things to be fast they had to be simple. One particularly bad culprit was the IP fragmentation fields, which introduced a lot of complex logic about splitting up and re-creating packets into the router which slowed things down considerably. In IPv6, this, among many other things was completely removed, allowing simple packet processing logic to be baked into the router hardware.
Then there is also the problem of the tragedy of the masses, or political will, or whatever else you want to call it. Despite all the downsides of IPv4, IPv6 adoption is still poor because it requires hardware support and as long as there are still people using IPv4 devices, backward compatibility must be maintained and so there is no great immediate short-term gain. It really makes you appreciate how wonderful life would be if we could just always get things right on the first try.
Next, you also have strong commercial interests, which is no surprise considering how much of the digital economy is powered by the internet.
On the producer side, we know that internet service providers are a type of autonomous systems that form the backbone of the internet. Autonomous systems (AS) are entities distinguished into different tiers (global, regional/national, local) that provide internet access to the end-user. When are AS’s incentivized to carry packets for other AS’s? Why should they advertise certain routes if it means having to take on more load on behalf of other entities? When and how do they peer with other AS’s to take shortcuts in the network? The answer all ultimately lies in whether they can find a way to make money off of it.
On the considerations for the consumer side of things, how do producers provide different levels of Quality of Service (QoS) depending on the internet subscription tier that the consumer is signed up for? How do you measure and ensure fairness for the protocols that we develop? Companies like Google have spent a lot of time thinking about such problems, developing transport-layer protocols like Quic which is used when connecting from the Chrome web browser to Google’s own servers.
A lot of the protocols that power the internet are also built on the trust that everyone behaves properly. But this is not always true. In 2008, Pakistan ordered their ISPs to block YouTube. They aimed to achieve this by sending an iBGP (internal BGP) announcement to “blackhole” all traffic to YouTube, i.e make it unreachable. But by error, they sent an eBGP (external BGP) announcement instead, effectively announcing to the entire world that they knew how to reach YouTube. But because their announcement had a smaller address block, it was considered more authoritative than YouTube’s eBGP announcement, meaning that very quickly all internet traffic intended for YouTube.com started going to Pakistan instead, effectively making the real YouTube unreachable for the entire world for almost two hours. As Hanlon’s razor goes, never attribute to malice that which can be explained by incompetence. When we do have a malicious actor though, just how bad can things get, and how do we guard against it?
Finally, there are many hardware and physical infrastructural factors. I am always impressed at how I still manage to have decent internet service in a large convention hall packed with people, each also using their own mobile devices. How do different WiFi access points (AP) perform collision avoidance to avoid transmitting at the same time, yet still provide good service? It turns out that channel reservation protocols are often too expensive in practice, and so virtual (and physical) carrier sense (i.e listen before you talk) is often preferred. Furthermore, the specific optimal placement of these APs actually involves a lot of measurements in 3D space, and it has become so advanced that centralized controllers for the APs can dynamically adjust their power and thus signal strength in response to live measurements of network interference.
All of these are barely scratching the surface of what I think makes the topic of computer networks so wild and wonderful, and if these sound like interesting things that you would love to learn more about, I would definitely recommend that you take the class!
Some thoughts from experienced software engineers
More than a few experienced software engineers have remarked to me during my internship that most developers have almost no clue about network engineering, despite it being really important in many applications in industry. For instance, a lot of optimizations for high-frequency trading are done in making the network stack faster, which is by far the largest bottleneck. On the other hand, many network engineers are also not the best software engineers, so people with skills in the intersection are highly valued and tend to be well-compensated. I’m not saying that making more money is the reason to take this class, but if you just happen to want something that is practical and might help your career prospects, you can’t go too wrong with this class.
Other courses at CMU
This post is written as part of a collection of posts to help shed light on some of CMU’s less well-known classes that I found interesting and useful, in hopes of encouraging more people to consider taking them. Check out the Course Reviews page for more.
I hope you found this post useful! Feel free to ask any questions in the comments section below. If you have taken the class before and would like to chime in with some thoughts, please feel more than welcome to also mention them below.
Acknowledgments
Special thanks to Jenny Fish for kindly proofreading and providing feedback on this post before it was published. She took Computer Networks the same semester that I did.
Related Posts: