Three Important Things
1. Challenges with Distributed Training
Training distributed models is challenging: current methods requires all nodes to be online and networked by high-bandwidth interconnects. Attempting to shard model weights, activations, and optimizer states in a way that can still keep the GPUs busy requires careful analysis and software engineering to get right. As the size of our clusters grow, the mean time to failure for any node is also decreasing, which can interrupt training.
The paper introduces Distributed Low-Communication (DiLoCo) training that tries to address these issues. This is an algorithm that requires low communication, is resilient against device failures, and supports heterogeneous devices.
2. DiLoCo
The main idea behind DiLoCo is actually quite simple.
There’s 2 optimization stages going on, dubbed the inner and outer optimizers.
In the inner optimization, each worker takes a sample of data from its shard of data, and optimizes its parameters independently for \(H\) steps. Only after these \(H\) steps does it share its updated parameters with all other workers, hence helping to hide communication overhead. In the paper, they used AdamW for the inner optimizer.
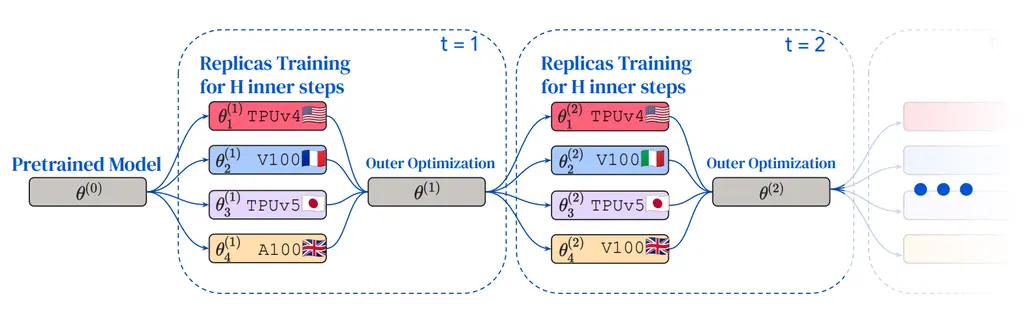
The outer optimizer then takes the average of the changes of all the inner gradients, and uses this to update the overall parameters for the next step. They used Nesterov momentum for this as they found that it empirically gave the best convergence results.

3. Resiliency to Compute and Communication Changes
They did some interesting ablations to show that this technique is resistant to both compute and communication changes.
Compute Changes
They tried various settings of how the total number of nodes in the cluster change over time (i.e constant, increasing over time, decreasing, halving, etc). It’s interesting to note that for strategies that use the same final total compute (i.e doubling/halving, or ramping up/down) that their final perplexity scores were very similar.
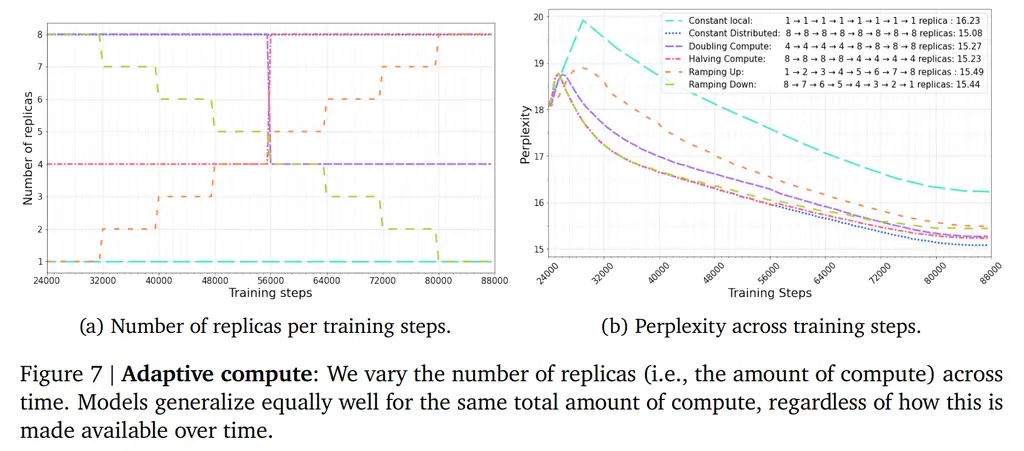
In general, schedules that used more compute overall had lower final perplexity.
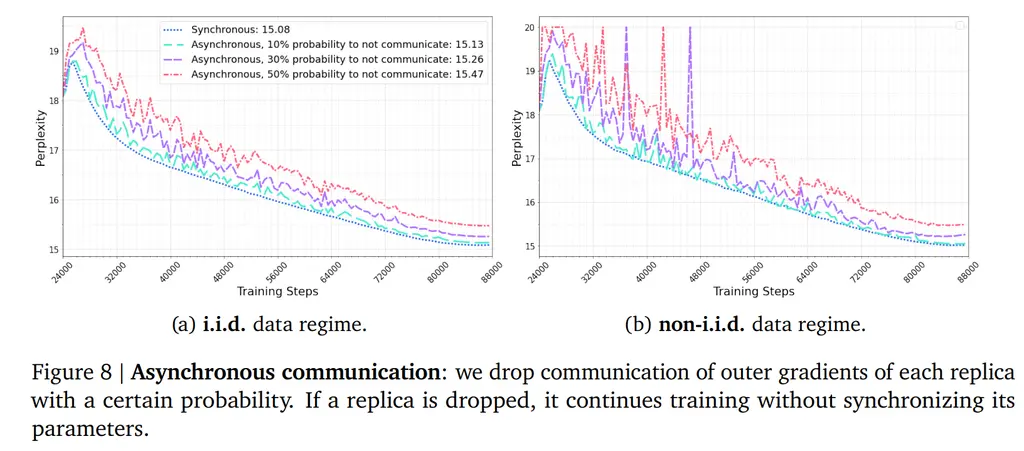
Communication Changes
On the network side of things, they tested how well training will proceed if each worker (out of 8 total) had a 10%, 30%, and 50% chance of failing to communicate their gradients. This will result in the isolated workers continuing to use their old gradients for the next step of inner optimization training. Surprisingly, even though the perplexity was spiky it still converged to nearly the synchronous case:
Most Glaring Deficiency
Perplexity is an ok metric to measure how training is improving over time, but may not necessarily correlate to downstream task performance.
Results would be stronger if there were downstream evals as well to ensure that there were no side effects to having such large inner optimization steps that cannot be glanced from just perplexity alone.
Conclusions for Future Work
Many traditional practices of model training (i.e we must update all weights after each backward pass!) are probably not strictly necessary for good convergence and generalization of training. Techniques like DiLoCo show that we can trade-off some of these for improvements in communication overhead and cluster resiliency with little impact on final model performance. This could pave way for more efficient and cheaper training of large models in the future.