Three Important Things
1. Existing Retrievers Suck
Existing dense retrieval techniques rely on supervised labels of queries to relevant documents. Using too few labels leads to worse performance than BM25 on any example that is out of domain.
One might then attempt to use a dense retriever trained on a large retrieval dataset like MS MARCO and use it zero-shot on new domains, but this is also frequently outperformed by BM25.
Is there any hope for a dense retriever that can be trained on the data in an unsupervised fashion that can match the performance of BM25?
To this end, the paper gives an affirmative answer, and introduces Contriever, an unsupervised technique that utilizes contrastive learning.
2. Contriever
In an unsupervised context, the only assumption made is that each document is unique in some manner.
Given the relevance score \(s(q, d)=\left\langle f_\theta(q), f_\theta(d)\right\rangle\) for a query \(q\) and document \(d\) where \(f_\theta\) is typically a Transformer-based model, the contrastive InfoNCE loss is given as:
\[\mathcal{L}\left(q, k_{+}\right)=-\frac{\exp \left(s\left(q, k_{+}\right) / \tau\right)}{\exp \left(s\left(q, k_{+}\right) / \tau\right)+\sum_{i=1}^K \exp \left(s\left(q, k_i\right) / \tau\right)}\]This is almost like a softmax with \(\tau\) being a temperature parameter. Minimizing the loss thus encourages it to assign high scores for relevant queries and documents, and vice versa.
3. Building positive & negative pairs
To create positive pairs, they considered the inverse cloze task, whcih uses a segment of the document as the query, and its complement as the document.
They also used independent cropping, which takes two independent spans in the document.
They also added random word deletion, replacement, and masking for data augmentation.
To create negative pairs, a simple approach is to take all other documents in a batch except the current document to be negatives, called “in-batch negatives”. However, this requires large batch sizes to work well.
To address the above, one method is to re-use samples from previous batches as negatives, allowing for more diversity and smaller batch sizes. They noted that this generates asymmetry in training, since the set of queries and keys are different, and during backpropagation the loss is only backpropagated through the queries whilst the keys are held constant. This could lead to training instability.
To alleviate that, they use a technique called MoCo, where two different networks for the queries and keys are used. The query network is trained with SGD as per usual, but the key network is actually updated as an exponential moving average of the parameters of the query network:
\[\theta_k \leftarrow m \theta_k+(1-m) \theta_q\]4. Results
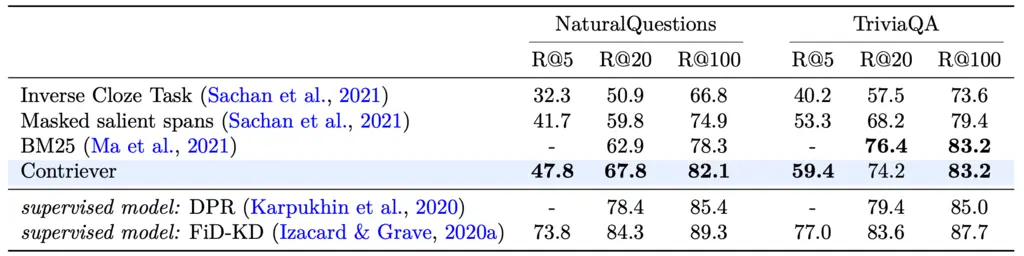
It’s pretty good against BM25 on unsupervised tasks, and both of them are generally much better than other unsupervised dense methods. It was surprising to me just how strong BM25 is as a baseline.
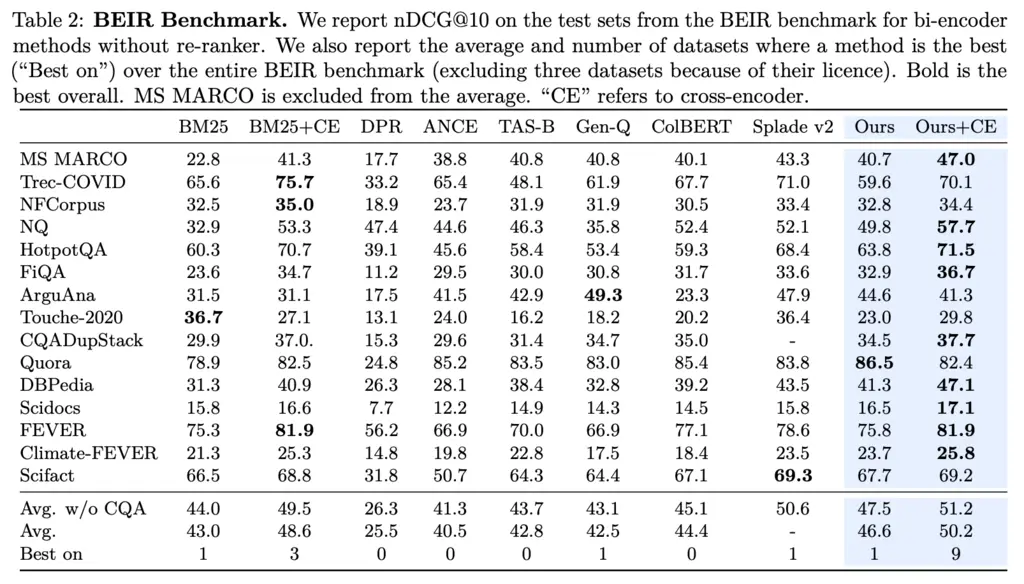
In the supervised setting, they’re also SOTA for some datasets, though I haven’t had time to look into any of the other methods other than ColBERT. +CE means that they added a cross encoder for re-ranking, which helps with nDCG scores as it is position-sensitive.
Most Glaring Deficiency
Would be interesting to know if there’s any kind of “scaling laws” if the data that it was trained in an unsupervised fashion was scaled up.
Conclusions for Future Work
Contriever is one of the most competitive & popular baselines for retrievers, and shows how unsupervised techniques have broad appeal.
Not really the contribution of this paper, but I also thought the method of using momentum updates for the key network in MuCo was really cool.