1. Generate-then-Read
Instead of the traditional “retrieve-then-read” pipeline, they propose a “generate-then-read” pipeline for RAG. This means generating a hypothetical document that may contain the answer, and using that to answer the question.
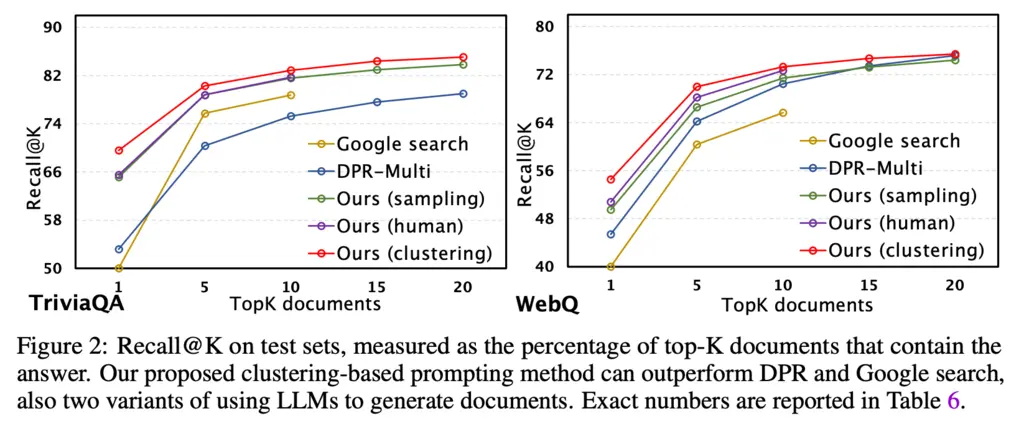
Instead of generating just a single document, they used a variety of techniques to increase diversity of the generated documents, such as diverse human-written prompts and sampling random few-shot examples of question-document pairs to seed it. There’s nothing really novel about the technique, but the surprising thing is that this actually works for popular Q&A datasets:
Most Glaring Deficiency
Some evals on proprietary/unseen datasets would be interesting. We all know it probably wouldn’t work, but it would be nice to confirm this, or otherwise be pleasantly surprised.
Conclusions for Future Work
Kind of a silly idea prima facie, but it’s quite cool that it works in some domains. Kudos to the authors for putting in the effort to try this out.