Three Important Things
1. Iterative Retrieval-Generation Synergy
Instead of just retrieving context and generating a response for RAG just once, we can iteratively perform this pgocess and give the LLM the opportunity to retrieve more relevant information in the next iteration. This is because there may be a semantic gap between the original question and the context needed to answer it.
For instance, in the example below which requires multi-hop reasoning, the model first retrieves that Jesse Hogan was the player who won the award, however hallucinated the wrong height.
During the second retrieval, it was able to retrieve the right context with the actual height, and can now craft the final answer.

They call their technique ITER-RETGEN. It works as follows:
- Start with user question \(q\)
- Query initial paragraphs \(D_{q}\)
- Get answer generation \(y_1\)
- Query new context given query and first geneartion, \(D_{y_1 \|\| q}\)
- Get answer generation \(y_2\)
- …and so on, until we have all \(T\) iterations.
- Return \(y_T\) as the final response
2. Evaluation Format
They used the following prompt to determine if the RAG answer is correct. They eschewed exact match (EM) metrics as it significantly understates the performance of the system, and was not sensitive to actual improvements in it. They called this method of evaluation Acc\(^\dagger\).
In the following task, you are given a
Question, a model Prediction for the
Question, and a Ground-truth Answer to the
Question. You should decide whether the
model Prediction implies the Ground-truth
Answer.
Question
{question}
Prediction
{model output}
Ground-truth Answer
{answer}
Does the Prediction imply the Ground-truth
Answer? Output Yes or No:
3. Results
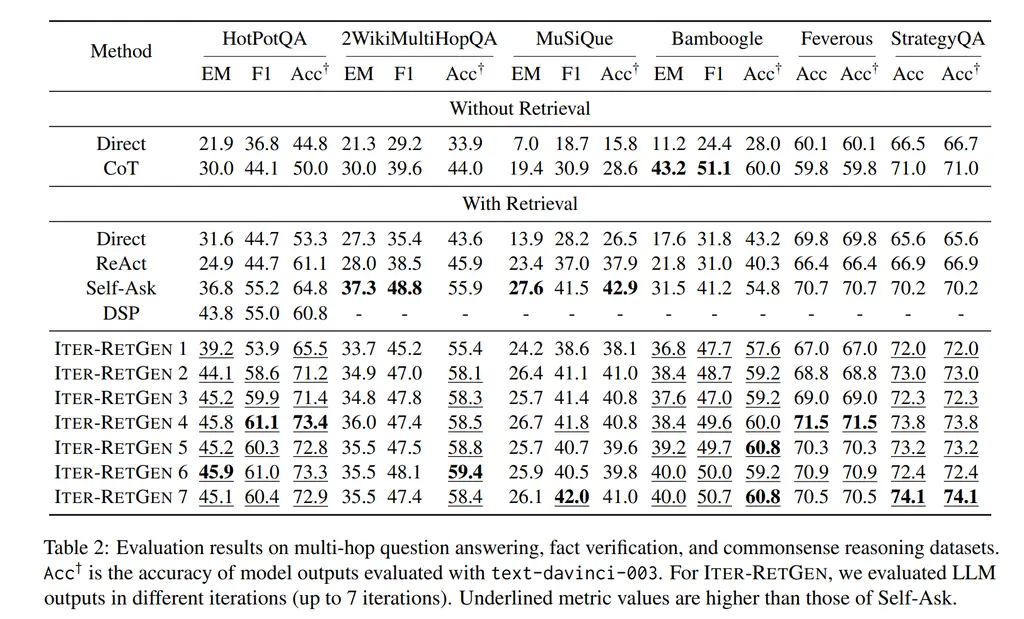
They found that the second iteration brought the most performance boost, and higher iterations generally performed better. The second iteration (ITER-RETGEN 2) was competitive with other SOTA methods like ReAct, Self-Ask, and DSP.
They also validated that their Acc\(^\dagger\) metrics were more accurate than EM by manually inspecting samples, and finding that in the overwhelming majority of the cases where Acc\(^\dagger\) and EM disagrees, Acc\(^\dagger\) was correct.
Most Glaring Deficiency
In practice due to varying difficulty of tasks it may be interesting to explore taking an adaptive number of steps based on whether the model now already has enough knowledge to answer the question.
In addition, there may also be value to keeping previously retrieved context, which could be explored.
Conclusions for Future Work
I suspect this paradigm works because it can be viewed as a form of advanced query re-writing, where the query now looks very similar to the target data due to inclusion of similarly relevant data chunks.