Two Important Things
1. Answer Summaries for Questions which are Ambiguous (ASQA)
Answering a long-form answer based off a set of relevant documents is essentially query-based multi-document summarization. Furthermore, such questions may be ambiguous.
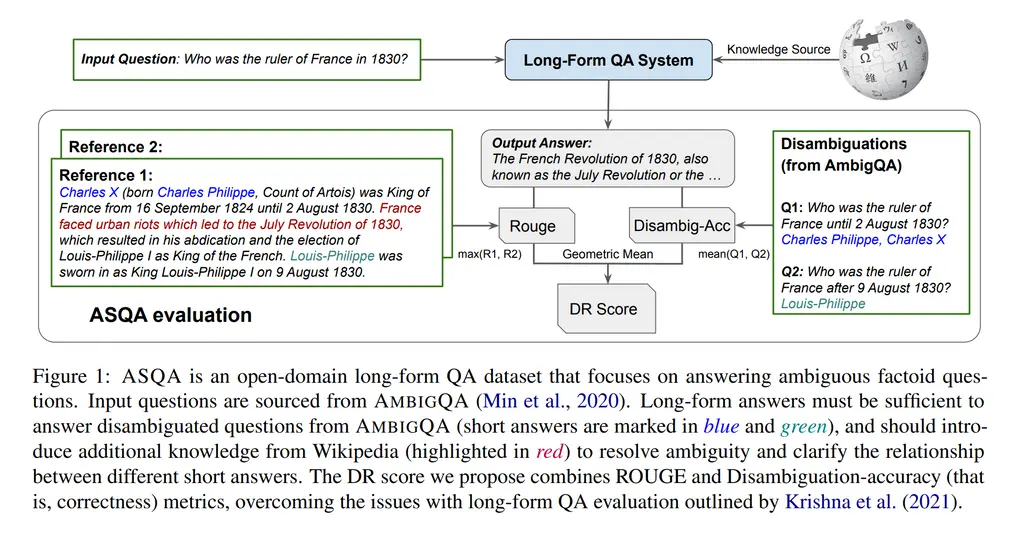
A good answer should address the ambiguity in the question, and synthesize all the valid short answers into a coherent long answer. For instance, the question Who was the ruler of France in 1830 is ambiguous since there were two rulers.
They use the following desiderata for a good long answer:
- Completeness. The long answer should contain all valid short answers.
- Comprehensiveness. The long answer should address source of initial ambiguity, and map the relationship between the provided short answers
- Fluency. Should be coherent and fluent
- Attributability. Long answer should be grounded in provided documents
They hired crowdworkers to annotate AmbigQA dataset to create the ASQA dataset that respects the above guidelines.
2. Evaluation Pipeline
They also came up with a new metric, the DR score for evaluating responses on their new ASQA dataset.
This DR score uses both the ROUGE score (measure of similarity between two texts based on overlapping n-grams) and they call disambiguation accuracy.
Disambiguation accuracy helps to address the many shortcomings of ROUGE (i.e semantically similar but syntactically different responses). It works by using an encoder model (Roberta) pre-trained on the SQUADv2 question answering dataset to generate the short answer based off of the long answer, and then computing the F1 score in terms of the set of tokens that appear (after normalizing it like removing irrelevant characters like punctuation).
Overall workflow:
Most Glaring Deficiency
I was really confused how they could use Roberta to generate text, since it’s an encoder-only model. Maybe they meant another model when they said SQUADv2 model.
Conclusions for Future Work
A good dataset should address the limitations of previous datasets that come before it, and with that, limitations in the evaluation techniques used.