Three Important Things
1. Can LLMs Effectively Use Long Context Lengths?
LLMs increasingly get longer context lengths due to improvements in architecture and positional embedding techniques, and the question now becomes whether they can effectively use this long context lengths.
To answer this, the authors conducted experiments on Q&A datasets where the correct answer is embedded within one of the documents provided as context, in addition to k-1 other distractor documents which are semantically close according to a Contriever, but do not contain the answer, such that this could simulate a real RAG system.
Here’s an example of an experiment setup:

They found a U-shaped curve across multiple models and retrieved document lengths:
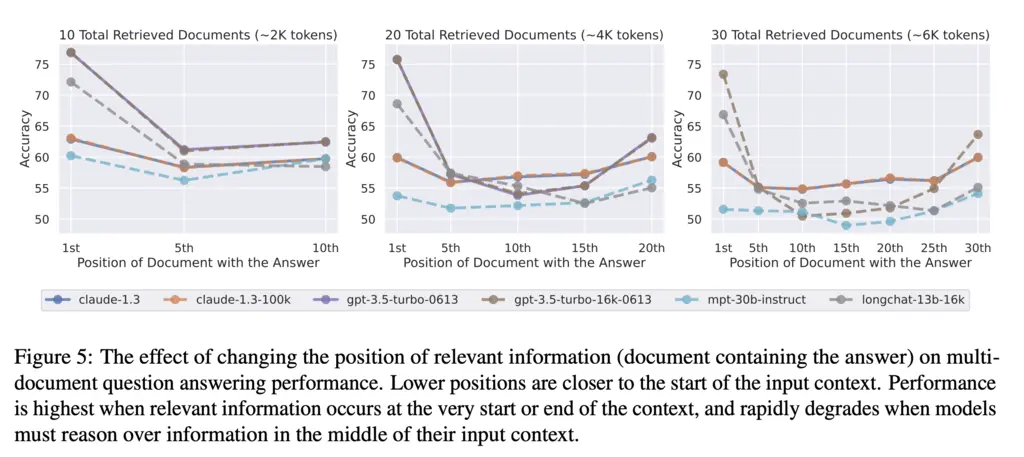
In fact, it could even be possible that when the relevant document is in the middle, providing context is more harmful than not providing context at all:
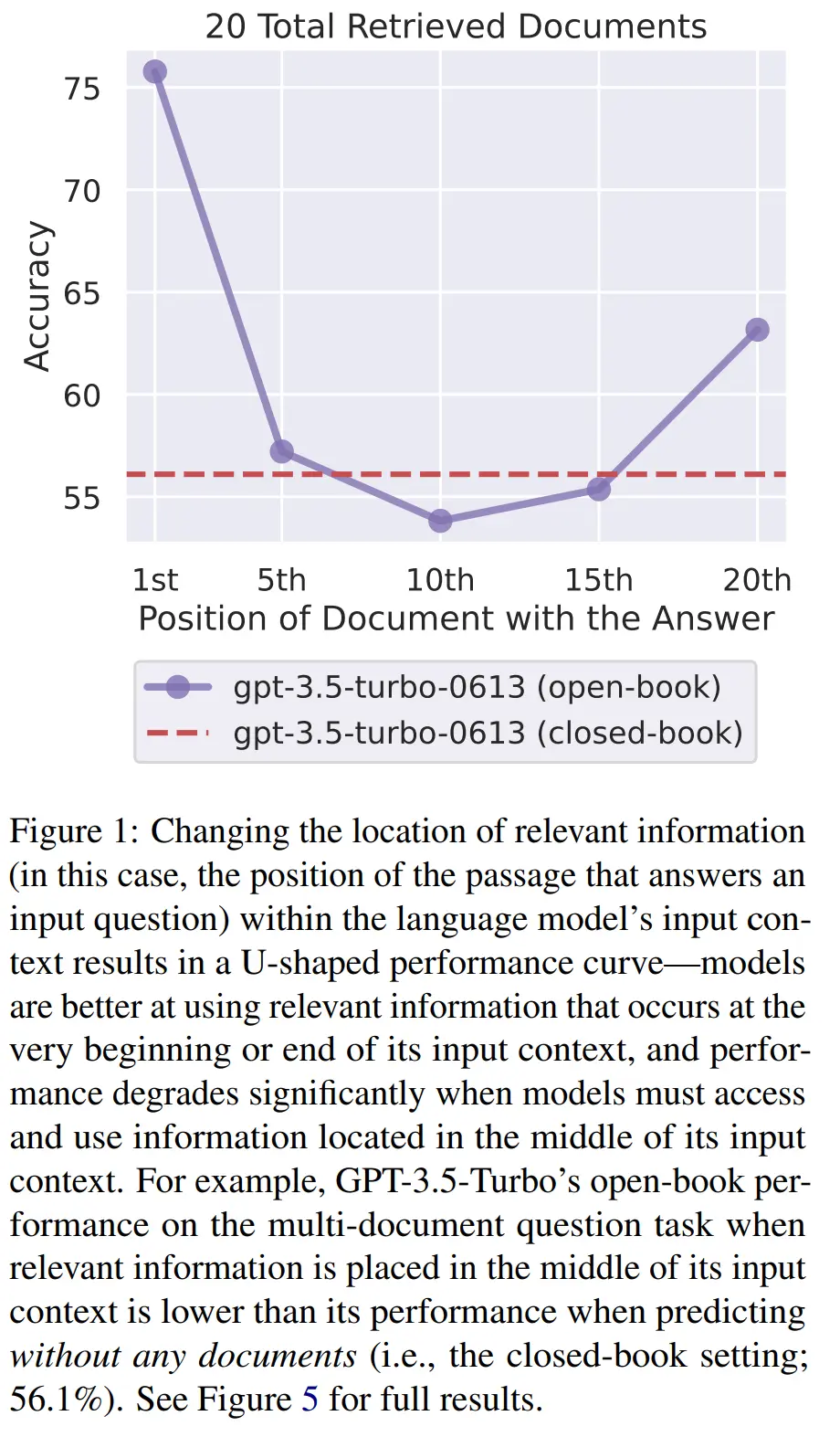
They term the improved performance at the start and ends primacy bias and recency bias respectively.
They also separately conducted a “needle-in-a-haystack” eval by giving the model k key-value pairs serialized as JSON, and found that while some models (i.e Claude 1.3) had perfect accuracy, other models tend to have worse accuracy in the middle. However, it should be noted that based on needle-in-a-haystack on recent models that this eval is more or less a “solved” problem with almost perfect accuracy across extremely long context lengths.
2. Place Query Before Context
One possible reason for the lost-in-the-middle phenomenom is that decoder models cannot attend to the query while contextualizing the documents due to how they process tokens from left to right.
To investigate if this was the case, they added the query both before and after context, and found that all the decoder-only models now achieve perfect accuracy.
3. Reasons for Lost-in-the-Middle Behavior
Non-instruction fine-tuned models are biased towards recent tokens, likely because the task of next-token prediction benefits minimally from interactions across long distances.
The question now is whether non-instruction fine-tuned models also exhibit primacy bias. One may be inclined to say no, and think that it is an artifact of instruction-tuning because instructions normally appear at the start of the document. But in fact they also exhibit primacy bias:
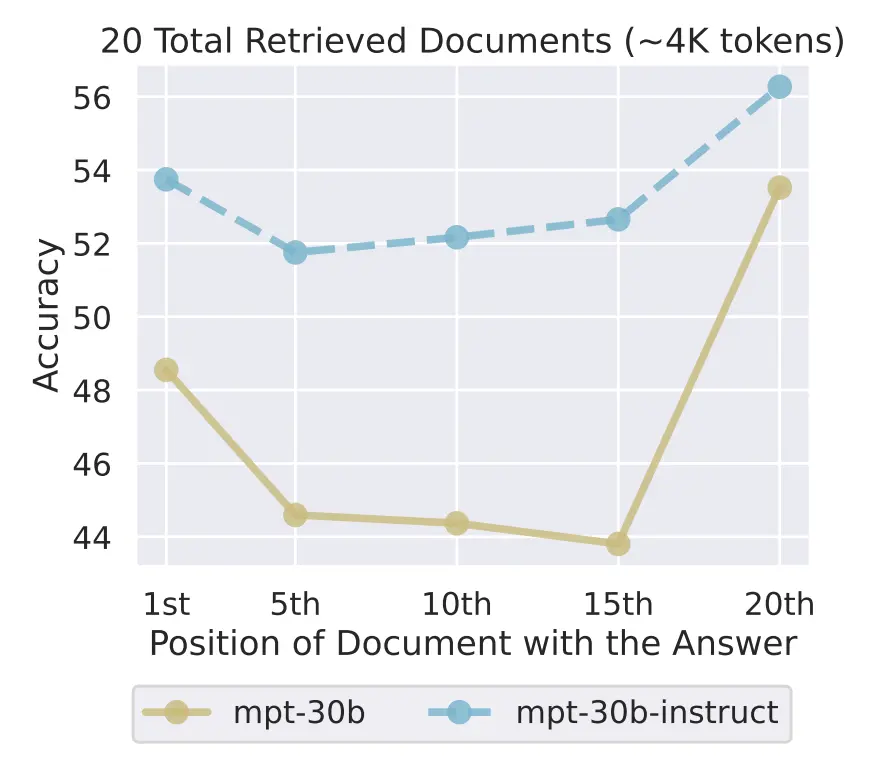
Most Glaring Deficiency
Due to the inconclusive answer on why lost-in-the-middle happens from the simple experiment conducted in the previous section, it would have been interesting to see how the attention mechanism activates across each of the documents as the position of the relevant document changes.
Conclusions for Future Work
- Put query both before and after context for decoder models
- As all models exhibit recency bias but small models don’t exhibit primacy bias, putting the most relevant context at the end may be helpful
- Or use something like LostInTheMiddleRanker: i.e if the top 10 relevant documents are labelelled 1 through 10, it would order them
[1 3 5 7 9 10 8 6 4 2]