Three Important Things
1. Generative Retrieval and HyDE
Back in 2022 when this paper was written, people performed dense retrieval by using two encoders, \(\mathrm{enc}_q\) and \(\mathrm{enc}_d\) for the query and document respectively, projecting them into the same embedding space, and taking its dot product:
\[\operatorname{sim}(\mathbf{q}, \mathrm{d})=\left\langle\mathrm{enc}_q(\mathbf{q}), \mathrm{enc}_d(\mathbf{d})\right\rangle=\left\langle\mathbf{v}_{\mathbf{q}}, \mathbf{v}_{\mathbf{d}}\right\rangle\]The problem with this approach is that optimizing for retrieval without the (query, document) supervised labels makes this an intractable problem.
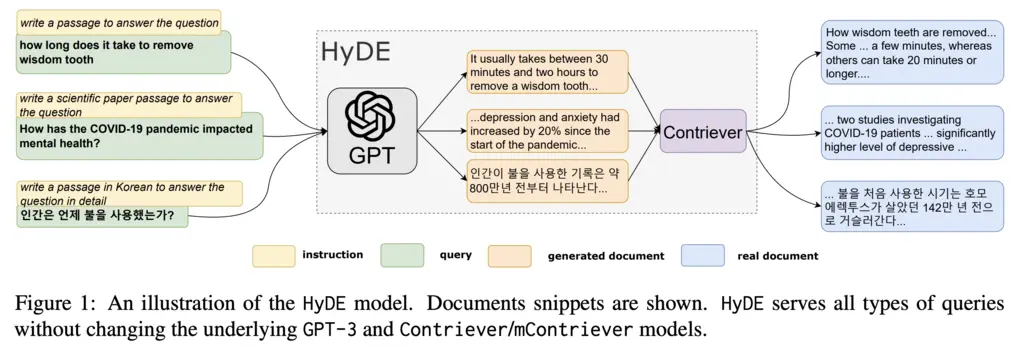
Instead, their insight is to perform this search in document embedding space by using a LLM to generate a hypothetical document, and then applying the same document encoder on it to generate embeddings. Document-document similarity is now something that can be captured easily with unsupervised contrastive learning techniques.
Since the documents generated are actually a probability distribution, we can take expectations:
\[\mathbb{E}\left[\mathbf{v}_{q_{i j}}\right]=\mathbb{E}\left[f\left(g\left(q_{i j}, \mathrm{INST}_i\right)\right)\right]\]In practice, what this means is we can sample \(N\) different hypothetical documents and take their average embeddings.
An example prompt for the FiQA dataset would be:
Please write a financial article passage to answer the question
Question: [QUESTION]
Passage:
2. Results
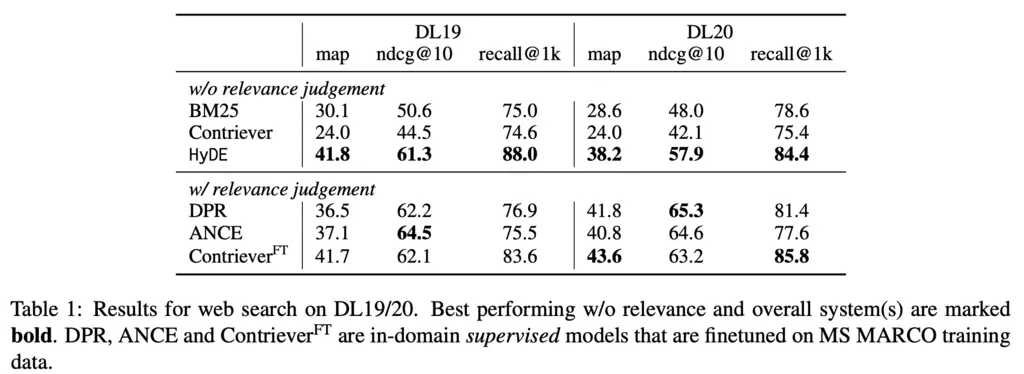
When relevance judgements (i.e labels) are not provided, HyDE performs much better than the non-dense BM25 baseline, and non-finetuned Contriever (it’s interesting that Contriever performs worse than BM25).
When labels are provided, HyDE is no longer relevant as it doesn’t require labels, but we see that even then there are a few datasets where HyDE performance comes close to the strongest model.
3. Usage Recommendation
HyDE can work well as an initial prototype of a search system, offering better performance than other relevance-free models.
However, as the search log grows, a supervised dense retriever can eventually be trained to replace HyDE.
Most Glaring Deficiency
There are probably techniques to improve the performance of HyDE further, by increasing the similarity of the hypothetical text to the retrieved documents if some labeled pairs are provided. This could capture things like style and format, and could be done as easily as few-shot prompting.
Conclusions for Future Work
Don’t rule out using LLM-generated data as an intermediate step in a pipeline in creative ways!
There’s also a technique called reverse-HyDE, where synthetic content/metadata is generated for each of the documents to increase the chances that relevant queries will be close (embedding-wise) to it.