Three Important Things
1. Rewrite-Retrieve-Read
Traditionally, RAG systems uses the retrieve-then-read pipeline. However, this means there is a gap between the query text and the knowledge it is meant to query.
For instance, the query
What 2000 movie does the song "All Star" appear in?
fails to retrieve any context containing the right answers, but the re-written query that aims to match the data distribution better
2000 movie "All Star" song
resulted in successful retrieval.
The paper uses this idea to introduce the Rewrite-Retrieve-Read paradigm, which performs a rewrite of the query before retrieving relevant documents, denoted in 2 different setups (b) and (c):
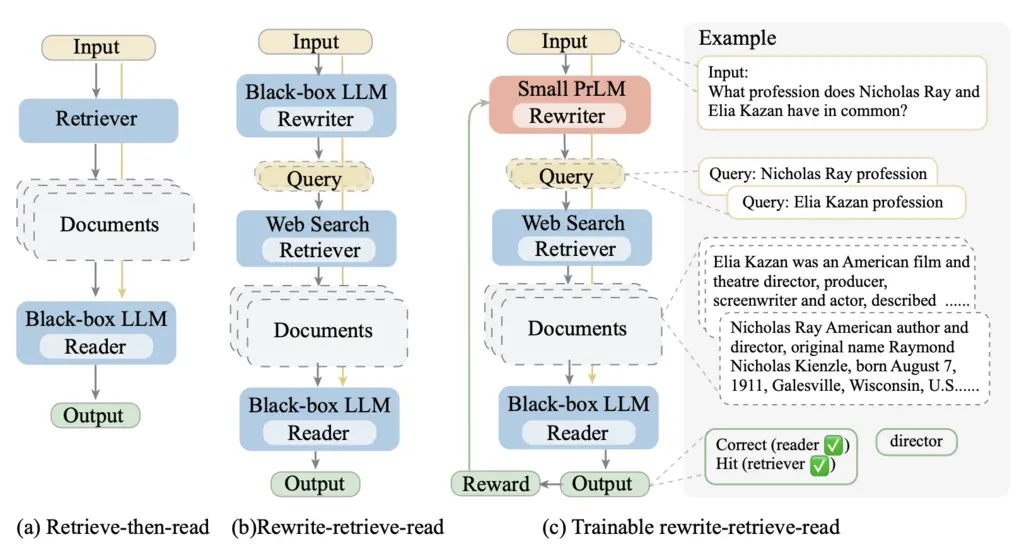
In (b), a LLM is prompted to rewrite the query. Here’s a sample prompt:
Open-domain QA:
Think step by step to answer this question, and provide search
engine queries for knowledge that you need. Split the queries with ’;’ and end
the queries with ’**’.
{demonstration}
Question: {x}
Answer:
Multiple choice QA:
Provide a better search query for web search engine to answer the given
question, end the queries with ’**’.
{demonstration}
Question: {x}
Answer:
In (c), a small model is trained by RL to perform query rewriting. How this is done is more involved and is explained in a subsequent section.
2. Results
There is proably no doubt that rewriting will improve performance, and the results does indeed confirm this is the case (compare Retrieve-then-read vs LLM rewriter):
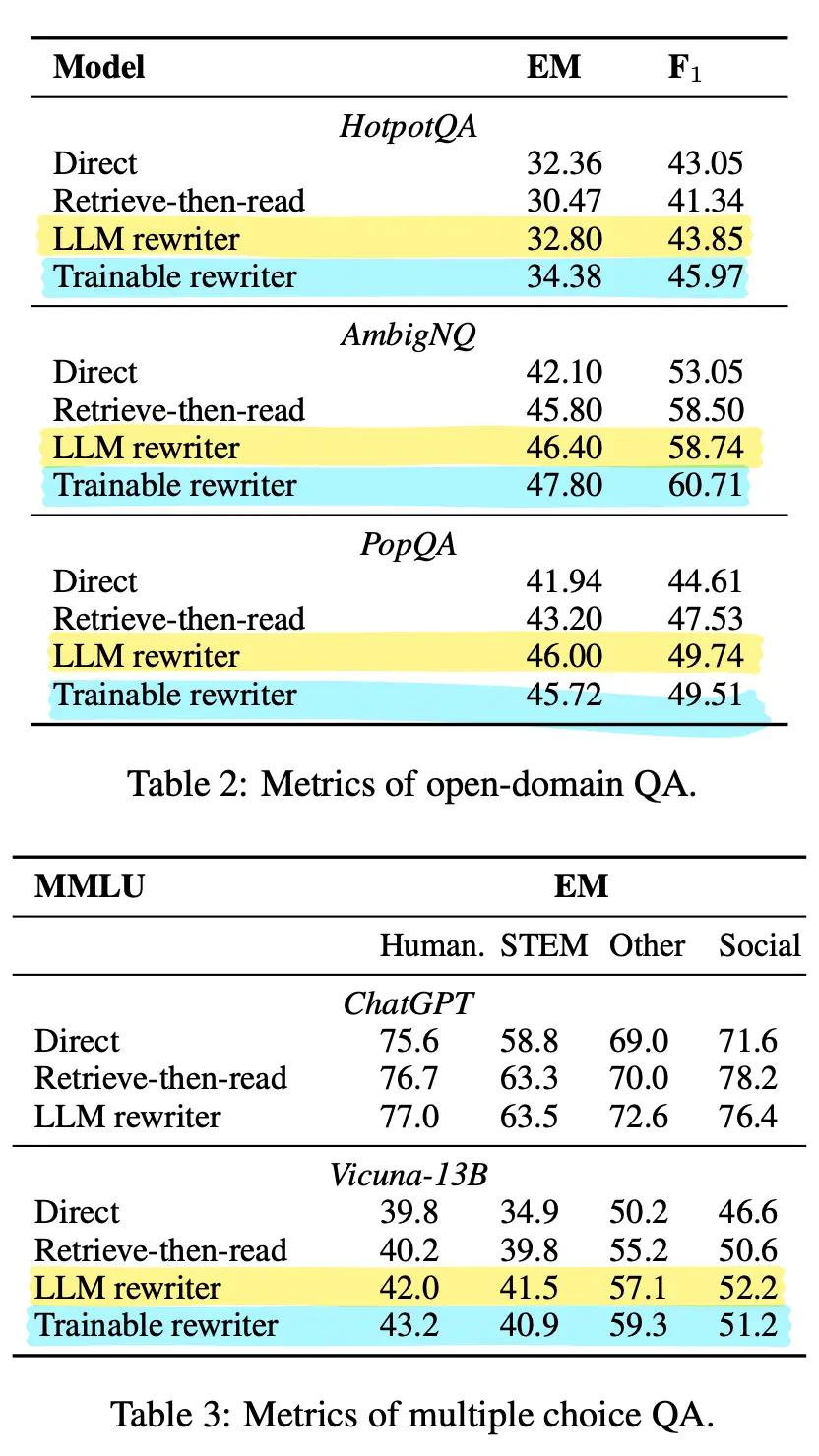
It was interesting to see that HotpotQA performed worse with RAG without rewriting, than without RAG at all. The paper says this is due to the complex multi-hop nature of the questions that causes direct retrieval to bring in noise instead of useful context.
What was interesting is whether the fancy RL small model (blue highlights) approach outperforms the naive LLM query rewriting (yellow highlights), and by how much. It generally helepd, with improvements similar to the lift from using RAG over direct answering. However, the improvements in both cases are still pretty marginal. My suspicion is that much of the knowledge of these Q&A questions are already in the pre-training corpus of the LLMs they used, which sells its main offering of helping with knowledge intensive tasks short.
3. Trainable LLM Rewriter
So how does the fancy RL small model work?
- They first collated a training dataset of good pairs of queries and re-written queries that do well.
- They fine-tuned this on a T5 model to warm up the model to be better at rewriting queries, like SFT fine-tuning before RLHF
- They used PPO to train the network to maximize rewards that come from the PPO KL divergence constraint, and whether the final answer generated from the retrieved context matches the golden label. They also mentioned using F1 score, though I’m not really sure how that is measured in the context of open-domain retrieval where there’s no way to actually compute the total number of true positives/negatives.
Most Glaring Deficiency
The results would be more convincing if the evaluation dataset is entirely composed of synthetic data that never appears in the pre-training corpus, and hence retrieval performance comes entirely from the capabilities of the RAG system.
Conclusions for Future Work
Query rewriting is now a standard practice in the toolbox of RAG techniques, confirming the importance of getting a high hit rate of retrieving relevant documents. They also replicated results from previous papers on how this was more important than improving the reader. Without good data at the start of the pipeline, everything else becomes harder.