Two Important Things
1. Addressing Corpus Quality
Note: I did not read this paper too closely, as I found it written in a rather confusing manner. It is likely that some/much of my interpretation of its points may not be faithful to the author’s intentions.
RAG pipelines suffer from a fundamental problem where the quality of generation is limited by the quality of the RAG dataset (which the paper refers to as “memory”).
The observation by the authors is that a RAG model can improve its output quality by first synthesizing the retrieved context to generate new content, that is added back into its knowledge base. The generated outputs are more in-distribution with what the model might see at query time, therefore resulting in better retrieval performance and final outputs.
They define a primal and dual formulation for RAG:
- Primal problem: better memory prompts better generation. This means better data and retrieved context leads to better outputs.
- Dual problem: better generation also prompts better memory. This means that when RAG systems can produce good outputs, it can also augment its own knowledge store with higher-quality data.
To utilize this insight, they developed a system called Selfmem
2. Selfmem
The framework looks like the following:
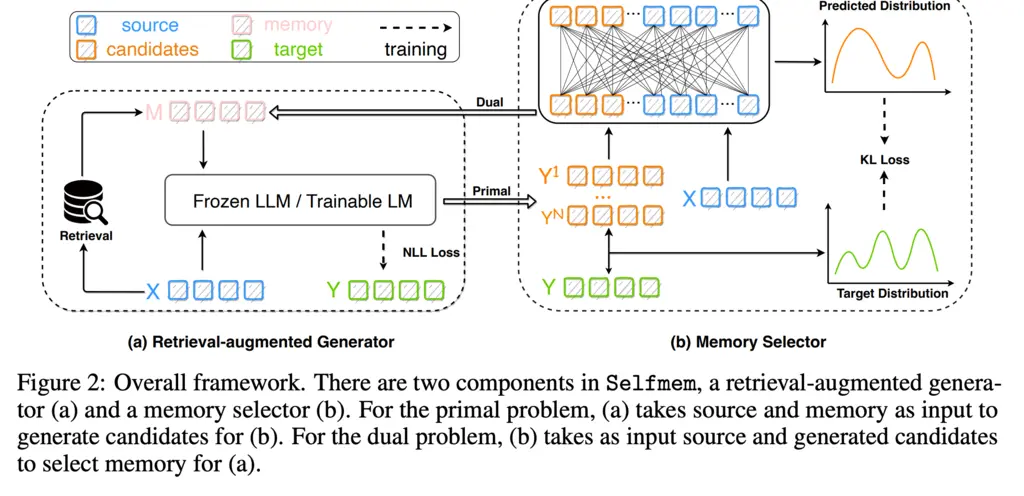
The two components are the retrieval-augmented generator, and the memory selector.
To my undersatnding, the algorithm works as follows:
- Get query
- Retrieve relevant chunks in dataset with a retriever
- Use LLM to generate pool of synthetic candidates based on the chunks
- Train a selector on the candidate pool using a selection metric, so the selector is now good at selecting good chunks to optimize the metric
- Using the trained selector, iteratively sample from the candidate pool, and use it to generate further candidates which are added back into the pool, until when metric converges for a validation set
- Generate final output with the best data chunk
Most Glaring Deficiency
The paper was not really written very clearly, and I personally found it really difficult to understand even though I believe the main points that the authors were trying to make are not that complicated.
Conclusions for Future Work
A RAG system can benefit from higher-quality output by bootstrapping itself by generating more high-quality data using data synthesized from its own data store.