Four Important Things
1. Effective Model Complexity
The paper comes up with a hypothesis to explain deep double descent. This involves introducing the notion of effective model complexity (EMC), which parameterized by the data distribution and choice of training procedure (i.e number of epochs).
The EMC is defined as the maximum number of training datapoints such that the expectation of the training error of \(n\) samples from the data distribution is less than some threshold \(\epsilon\). In other words, it is the maximum number of samples which it can interpolate almost perfectly.
They hypothesize the following, supported by empirical results:
-
Under-parameterized regime: if EMC is sufficiently smaller than \(n\), any perturbations of the training procedure that increases its effective complexity decreases test error
-
Over-parameterized regime: if EMC is sufficiently larger than \(n\), any perturbations of the training procedure that increases its effective complexity decreases test error
-
Critically parameterized regime: if EMC is around \(n\), then a perturbation of the training procedure that increases its effective complexity might decrease or increase test error
2. Model-wise Double Descent
They first conducted a series of experiments to understand the double descent phenomenom as you scale up model size.
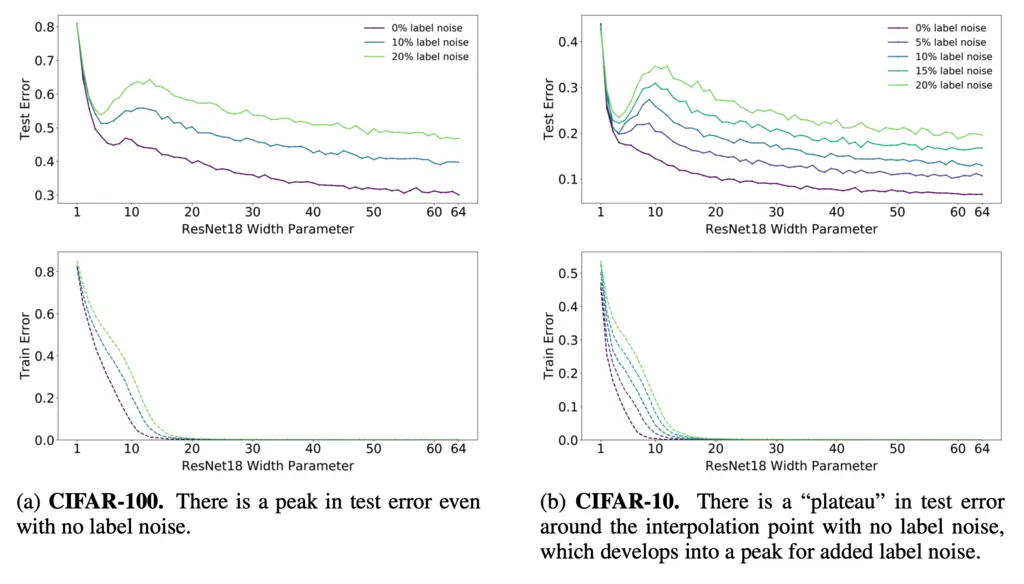
They saw double descent even in the absence of label noise (which happens in practice due to imperfect data) in the case of CIFAR-100, and that the double descent peak becomes more prominent as label noise increases.
They hypothesized that this could be because at the interpolation threshold (i.e where EMC=\(n\), so there is 0 train error), the model does not have any extra capacity and hence there is only a single model that can interpolate the train data, making it sensitive to noise in the training data.
3. Epoch-wise Double Descent
They also looked at how double descent manifests as a function of training time:
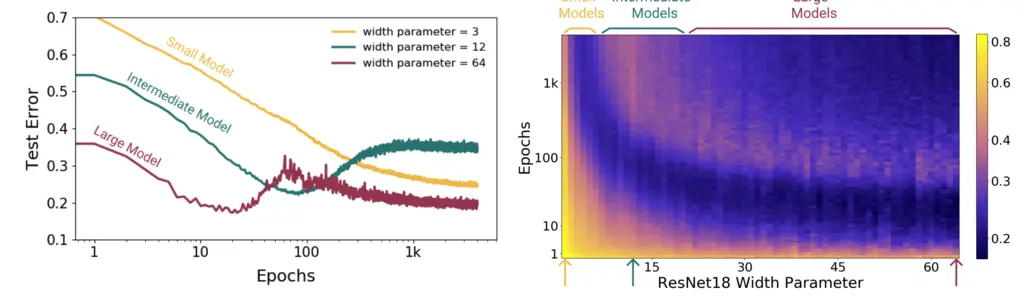
Here, they found that intermediate models follow the classical U-shaped curve, while the overparameterized models exhibit double descent. Small models had decreasing test error as per their hypothesis, as increasing epochs increases EMC.
This contradicts conventional wisdom which would have predicted a U-shaped curve for all 3 cases.
4. Sample-wise Non-Monotonicity
This experiment was the one that led to the most surprising conclusion, and is not directly implied by double descent.
Here, they experimented with changing the number of training samples, which causes the model to go from an over-parameterized to under-parameterized regime:
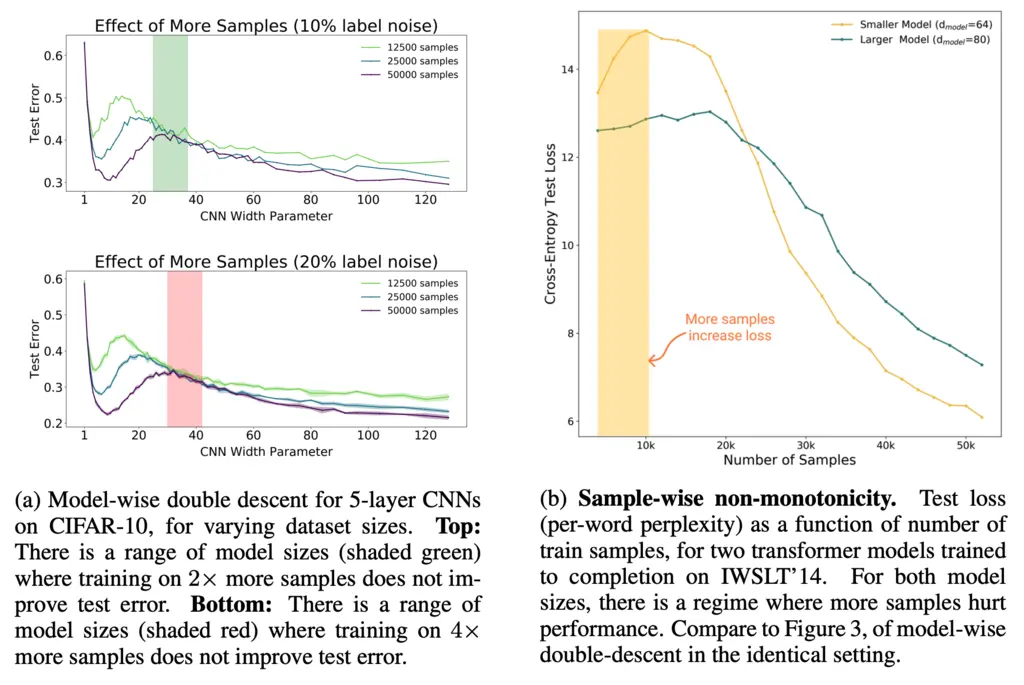
Having more data is uncontroversially considered good among both statisticians and machine learning theorists, but in fact there is a region (shaded in the diagrams) where a model trained on more data actually underperforms one trained on less.
Most Glaring Deficiency
It was unclear what the scope of training procedure entails, which made it hard to formally define and reason about the experiments that could be conducted to either further validate or disprove their hypothesis.
Conclusions for Future Work
The EMC framework shows the limitations of Rademacher complexity and VC theory in describing the behavior of over-parameterized models, since both of them only consider model complexity but not the training procedure or number of samples.
Understanding how deep learning actually works will probably require (yet another) rethinking how we model it.