Three Important Things
1. MIPRO
This paper introduces MIPRO (Multi-prompt Instruction PRoposal Optimizer) for optimizing multi-stage prompts. Multi-stage here means that there is a chain of LLM calls required to solve the task, usually done so that a complex task is broken down into simpler sub-tasks.
The paper builds on OPRO (see paper summary here), and generalizes it to multiple stages. It also optimizes both instructions and few-shot examples, instead of purely instructions in the case of OPRO.
2. Bayesian Surrogate Model
It was disappointing that the paper was not clear on how MIPRO works exactly, in particular how the Bayesian optimization part fits in.
From my understanding, MIPRO works as follows:
- There are many modules to optimize (stages in the LLM pipeline)
- Each module has instructions and demonstrations that can be optimized
- It uses the Tree-structured Parzen Estimator as a surrogate model to decide
- which modules to optimize, and then come up with a partial assignment of new values for those variables
Why the surrogate model? In Bayesian optimization, the objective is assumed to be expensive to evaluate, and therefore we make use of a cheaper surrogate model which is a proxy of the objective function. The surrogate model thus helps to decide which point to evaluate next.
However, since this is only a partial assignment, it was unclear how the assignments of the other modules were decided.
3. Results
They had a few variations of MIPRO, but the most important distinction is between whether they optimized instructions only (0-shot), demonstrations only (few-shot), or both.
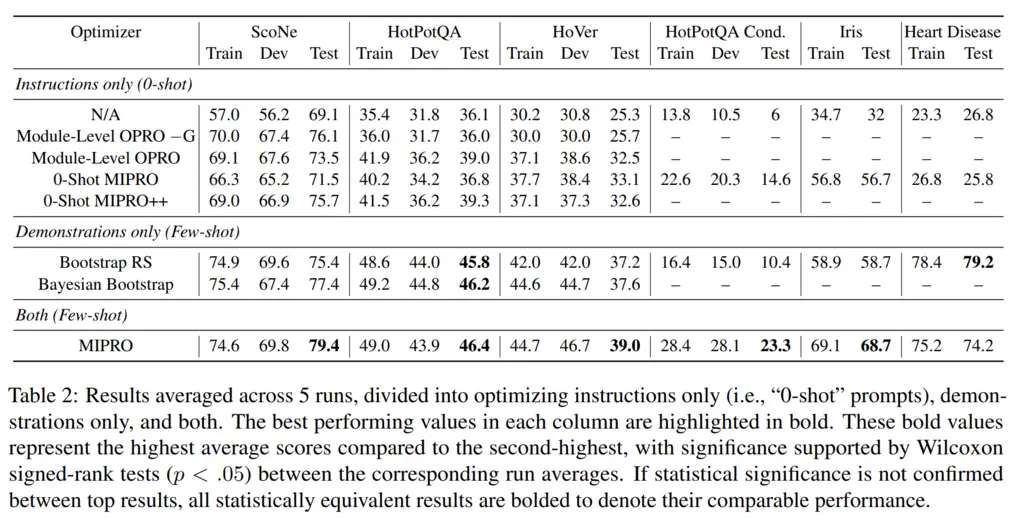
The table above shows that on almost all tasks except for HotPotQA Cond, optimizing for demonstrations only outperforms optimizing for instructions only, sometimes by a significant margin.
The only exception was HotPotQA Cond, a dataset they created off HotPotQA that had more complicated conditional logic in it which was hard to elicit fully with just examples.
Most Glaring Deficiency
The most interesting part of the paper was not well-explained. I am not an expert in Bayesian optimization and was unable to confidently understand how their optimization framework works even after re-reading several times and also going through the description of the algorithm in the appendix. An example run-through would have been helpful.
Conclusions for Future Work
Improving few-shot examples are more helpful for improving performance when instructions are not too complicated.
When instructions are complicated, optimizing for those is more helpful.