Three Important Things
1. Prefix-tuning
Prefix-tuning is billed as an alternative to fine-tuning or in-context learning (ICL).
In ICL, a key challenge is that the right prompt must be found to ensure that the desired distribution of output tokens for input tokens to perform some task is achieved. However, optimizing over discrete tokens for this prompt is computationally challenging.
In prefix-tuning, they instead add a fixed-length prefix that applies to all layers of the Transformer, and optimize for this prefix:

In this setup, we don’t use the prefix portion for generating any outputs (it comes before the input after all!), but still keep the prefix activations at each layer for each forward pass so that they can be used for self-attention in each Transformer block.
2. Resolving Unstable Optimization
The authors found that training all the prefix parameters directly led to unstable optimization and a slight drop in performance.
Originally, they had to train the \(P_\theta \in \R^{\left|\mathrm{P}_{\mathrm{idx}}\right| \times \operatorname{dim}\left(h_i\right)}\) matrix of parameters, where \(\mathrm{P}_{\mathrm{idx}}\) is the set of prefix-tuning indices, and \(\operatorname{dim}\left(h_i\right)\) is the hidden dimension of the Transformer.
To address this, they instead associated each prefix index \(i\) with a smaller number of parameters for a new overall smaller matrix of \(P_\theta^{\prime}\), and used a MLP network to increase its dimensionality like a decoder. Formally, this is given by \(P_\theta[i,:]=\operatorname{MLP}_\theta\left(P_\theta^{\prime}[i,:]\right).\)
Once training is complete, they took the actual output parameters to use as the prefix, and could drop the MLP and \(P_\theta^{\prime}\).
My guess for why they did this is because given the small size of the fine-tuning dataset, it’s likely hard to reach convergence if there are a large number of parameters to optimize.
3. Why Not Just Optimize Embeddings?
A natural ablation to ask would be, why don’t we simply optimize for continuous embeddings for the prefix, instead of activations at every layer?
They tried this, and also attempted infix-tuning where they fine-tuned on parameters between the input \(x\) and output \(y\) (i.e \([x; \text{INFIX}; y]\)), and showed that both performed significantly worse compared to prefix-tuning (first row):
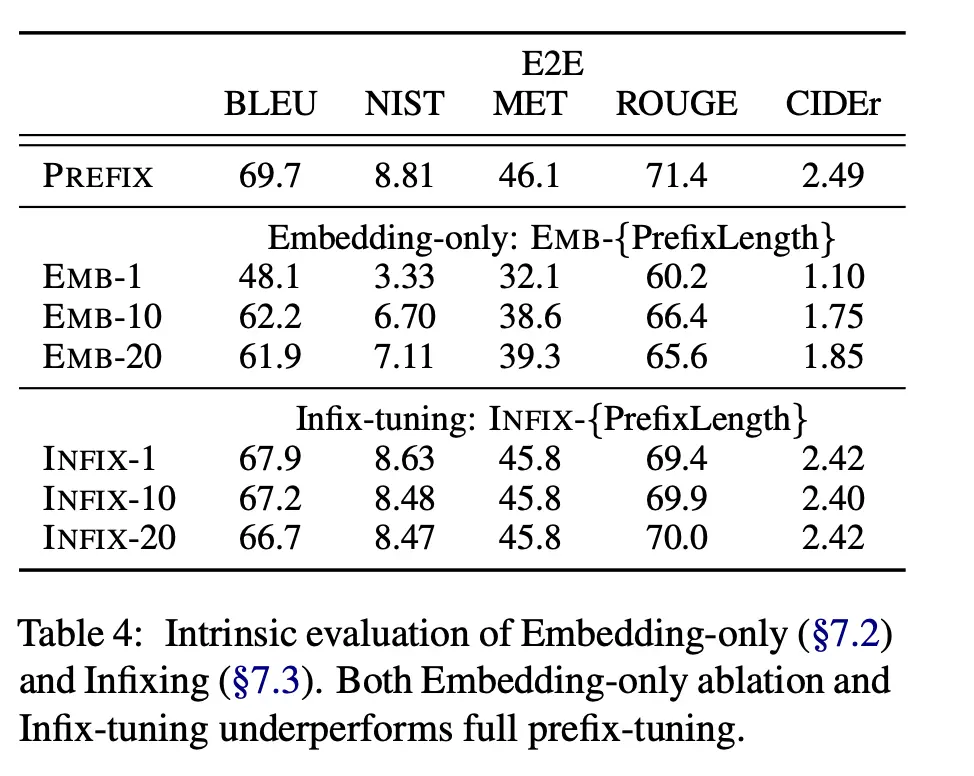
This suggests that just training the embedding layer is insufficient as it is not sufficiently expressive.
They also found that initialization with task-relevant words helped to improve final performance after training.
Most Glaring Deficiency
They only performed evaluations on two rather simple tasks, summarization and table-to-text. Perhaps it was quite impressive back then in 2021 when the paper was published, but now these two tasks are considered so simple that ICL can easily address them.
Conclusions for Future Work
Consider ways to perform relaxations from discrete to continuous space so we can make use of our machinery to optimize things.