Three Important Things
1. Repo-Level Prompt Generator
A limitation of code LLMs like Codex is that they perform poorly on large codebases as all the code cannot fit into the context window.
The paper introduces the Repo-Level Prompt Generator (RLPG), which is a way of retrieving relevant context for the prompt (i.e other related files, function definitions), in hopes that the generated code that relies on this prompt with more useful context will be better. They then feed this prompt into a Codex model.
In this paper, they call the place to infill generated code a “hole”.
RLPG works by generating prompt proposals, which is a combination of a prompt source and prompt context type.
The prompt source identifies which file to get the relevant context from, with the following categories:
- Current file (with respect to the hole)
- Parent class
- Import files
- Sibling files
- Files with similar names
- Child class
- Import of parent class
- Import of sibling files
- Import of files with similar names
- Import of child class
Given a prompt source, the prompt context type determines what to extract from the prompt source, with the following categories:
- Post Lines (all lines in the current file from the end of the hole - this only applies to current file)
- Identifiers
- Type identifiers
- Field declarations
- String literals
- Method names
- Method names and bodies
An overview of the RLPG framework is given below (I personally found this diagram more confusing than helpful, so skip it if you wish):
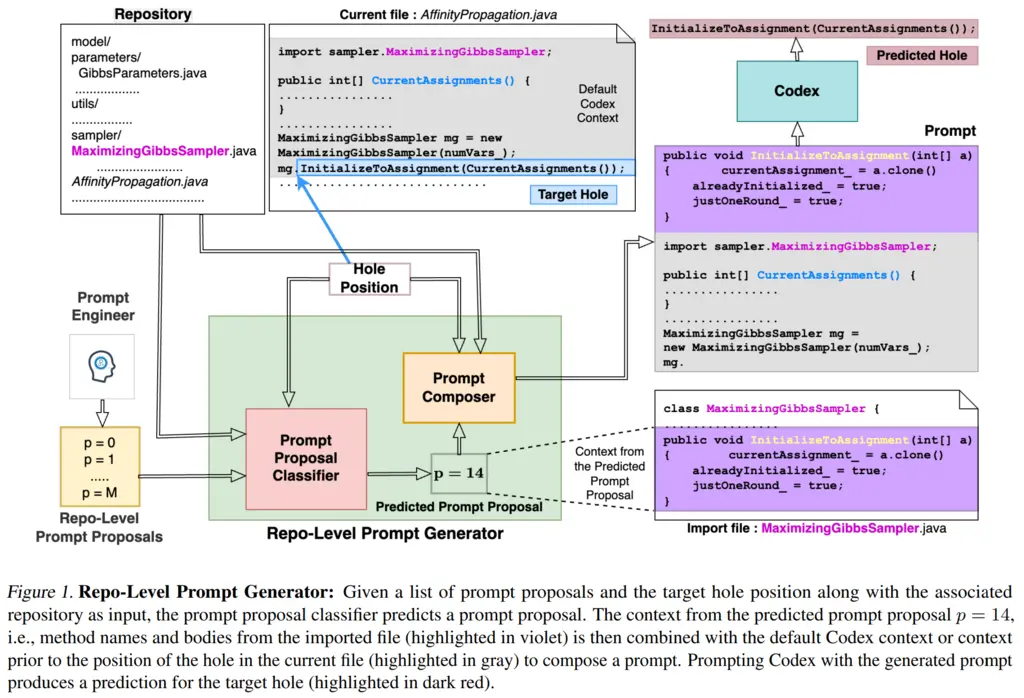
2. Prompt Proposal Classifier (PPC)
While we have a RLPG that generates a bunch of prompt proposals, it would be expensive to try all combinations of prompt proposals to see which one works.
Instead, the authors introduce a Prompt Proposal Classifier (PPC), which given a hole position, determines which prompt proposal has the highest probability of success, where success means that Codex generates the exact same code as what was in the hole after being fed that prompt.
They introduce two variants of PPCs: the RLPG-H and RLPG-R (it was unclear to me what H and R stands for here).
RLPG-H
In RLPG-H, they take the two lines before and two lines after the hole, feed it into the encoder \(F_\phi\) and take the encoded [CLS] token as an encoded representation of the surrounding context, and then feed it through a two-layer neural network with final sigmoid activations as predictions:
Hence the idea is that the encoded representation of the context might serve to have useful features to predict which prompt proposal might work best.
RLPG-R
In RLPG-R, they go a little further than RLPG-H and on top of obtaining the [CLS] token for the representation of the hole context \(H^h\), it takes advantage of the attention mechanism by treating that as the query, and also encoding the produced prompt context as the keys and values:
They then apply the multi-head attention module on it, and pass the result through a similar two-layer neural network:
\[\hat{y}_p^h =\operatorname{sigmoid}\left(W_p G\left(\text { MultiHead }\left(Q^h, K_p^h, V_p^h\right)\right)+b_p\right)\]We might think this may perform better, since it incorporates the attention mechanism between the prompt and the hole context (and RLPG-H does not even have access to the prompt contents), but surprisingly RLPG-H performs slightly better on evaluation:
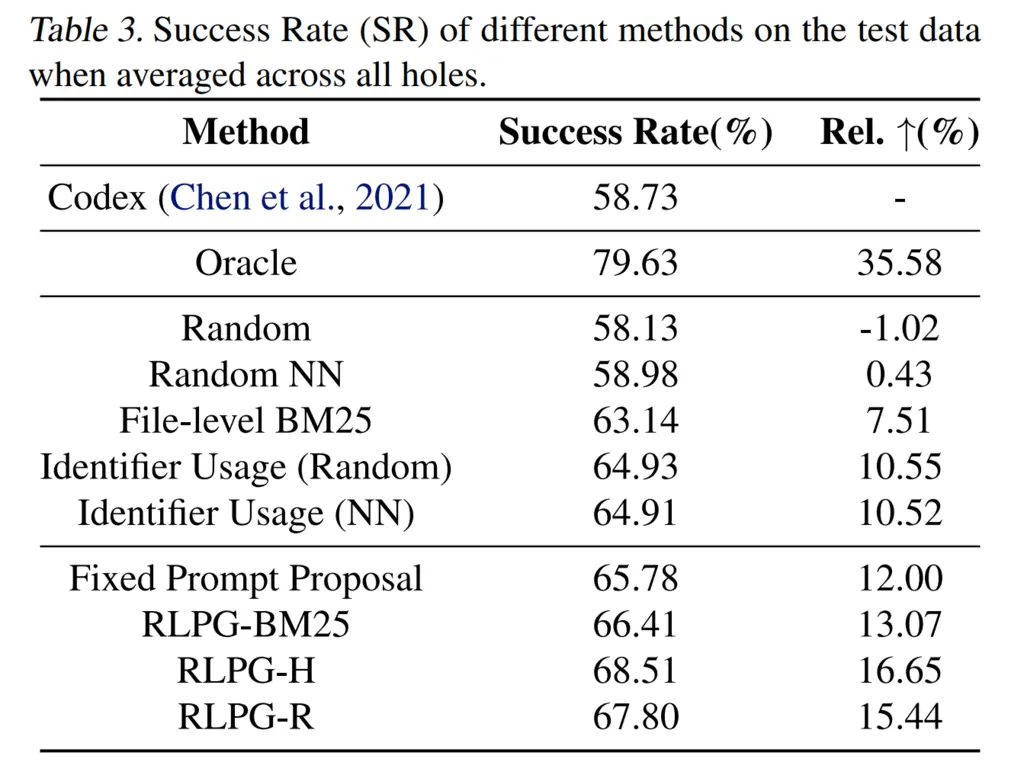
3. Performance of Prompt Proposals
With respect to the previous figure, we also notice that simply using any prompt proposal also performs better than default Codex. In fact, the authors noted that many of the prompts look like a mess with mashed-up contexts, and still performed better than the default Codex. This indicates that it is worthwhile to add any sort of context and not worry too much about ordering.
It is also interesting to note the prompt proposals that had the highest success rates
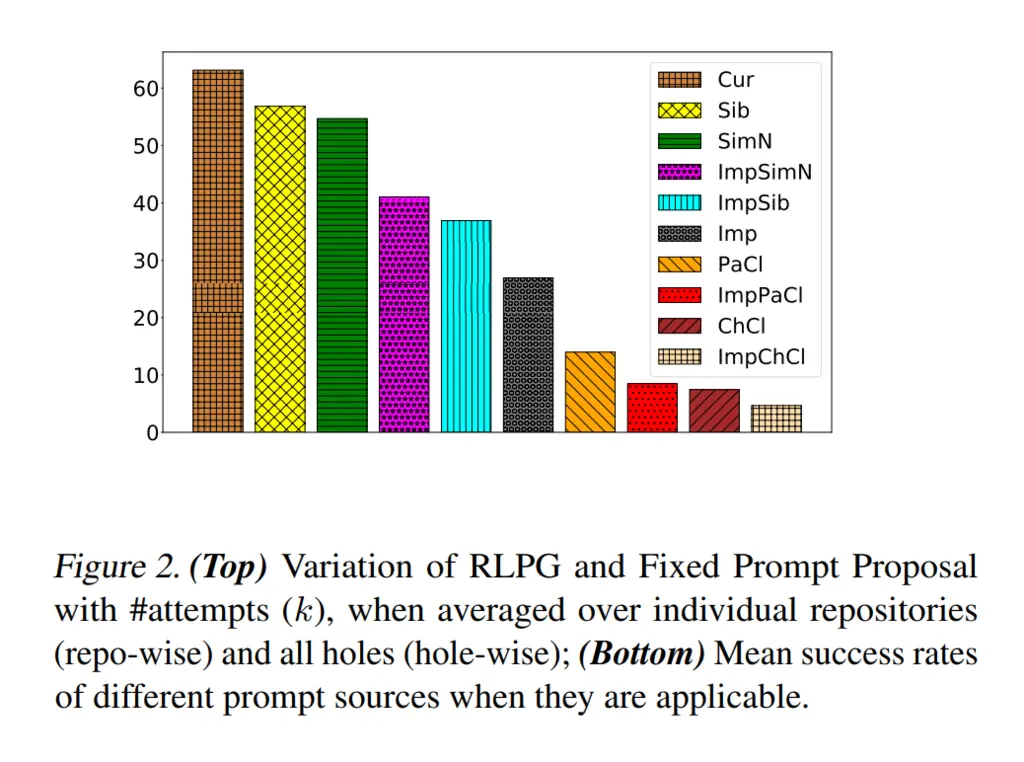
Unsurprisingly, having additional context from the current file helped the most. This was then followed by sibling files, and then files with similar names, and then the imports.
Most Glaring Deficiency
The prompt generation techniques are not mutually exclusive, and it seemed likely that they could be combined to achieve even better results, especially if we have not yet exhausted our context window. However, this direction was not explored in this paper, and as mentioned in the paper is left to future work, and it was also stated that they have promising initial results.
For instance, we might think that having relevant headers from an imported library and the relevant function definitions and bodies from a sibling file might cause it to perform even better, like the kind of information a normal developer would want.
Conclusions for Future Work
When there is more information than context, prompt generation becomes key to selectively choose information that would be the most helpful to the task at hand for the LLM. We can utilize similar techniques as this paper to augment our prompts with additional information, and note that even simple methods like randomly choosing additional context could already cause it to perform better.