Three Important Things
1. Ground Truth Labels Matter Little
This paper aims to make headway in understanding why in-context learning works. In-context learning, also known as few-shot learning, is where a few examples of input-label pairs are supplied to the model as part of the prompt.
Surprisingly, the authors found that randomizing the labels only had a slight impact on the accuracy of tasks that GPT-3 was evaluated on, and still performed much better than when no labels were supplied:
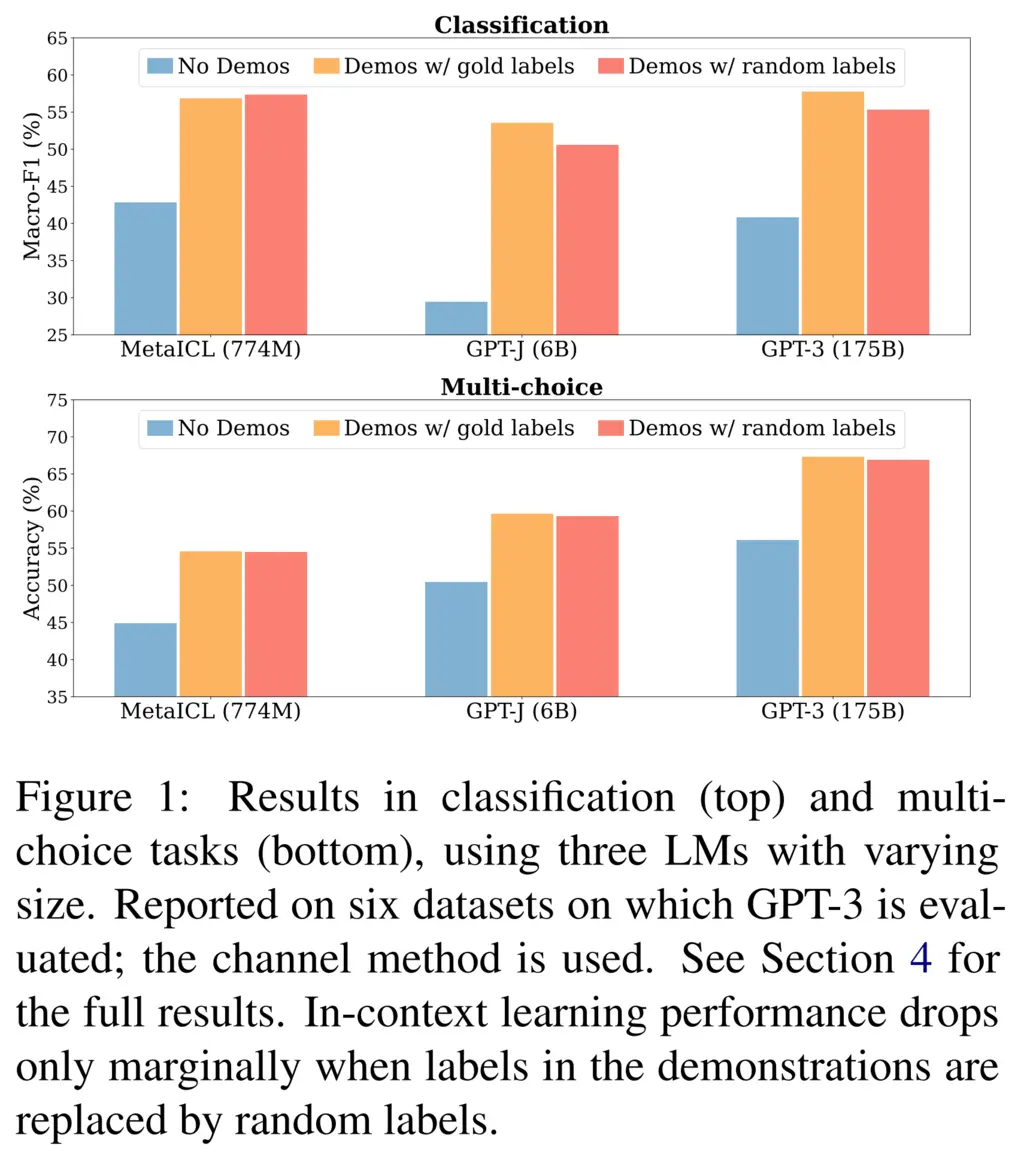
2. Number of Correct Labels Does Not Matter
The authors also tried varying the proportion of correct labels supplied (out of 16 in-context examples), and found that this did not really affect accuracy:
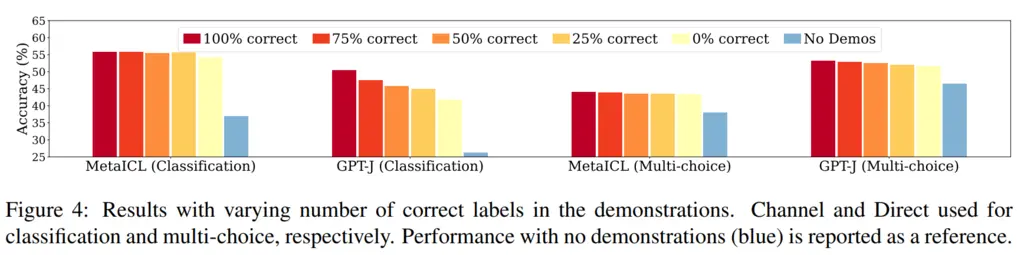
3. Why In-Context Learning Works
The previous two observations hence suggest that the performance gains from in-context learning vs zero-shot learning is due to the specification of the input space and label space to the model, and not because the model actually tries to learn from the supplied input-label pairs.
In fact, based on the results the model largely ignores the correspondence of the input-label pairs, and instead uses its own priors during pretraining for the output.
Most Glaring Deficiency
As noted in the paper, a key limitation of this result is that the tasks evaluated on are all NLP tasks, where the model already has some strong priors from pretraining. It could be possible that having gold (i.e ground truth) labels becomes more important for more specialized tasks.
Conclusions for Future Work
Even if we only have unsupervised data, we can still benefit from few-shot learning by assigning these unsupervised samples some labels from the expected target distribution.