Three Important Things
1. Deep Neural Networks Easily Fit Random Labels
It is an open problem as to why over-parameterized neural networks can generalize well even in the absence of regularization, as conventional wisdom would lead us to believe it should overfit to the training data.
To this end, people have applied classical learning theories like VC (Vapnik–Chervonenkis) dimension, Rademacher complexity, and uniform stability to argue that if the complexity of the network is bounded in some way, then it will generalize and not overfit. Specifically:
-
VC dimension: the VC dimension of a classifier is the largest number of points that it can classify correctly, for all possible assignments of their labels. So a classifier with VC dimension \(n\) can perfectly fit any labeling of \(n\) datapoints.
-
Rademacher complexity: the Rademacher complexity \(\hat{\mathfrak{R}}_n(\mathcal{H})\) on a hypothesis class \(\mathcal{H}\) on \(n\) datapoints \(x_1, \cdots, x_n\) is defined as
\[\hat{\mathfrak{R}}_n(\mathcal{H})=\mathbb{E}_\sigma\left[\sup _{h \in \mathcal{H}} \frac{1}{n} \sum_{i=1}^n \sigma_i h\left(x_i\right)\right],\]where \(\sigma\) is drawn according to an \(n\)-dimensional \(\{-1, +1\}\) Rademacher distribution, and we can think of the supremum \(h\) for each \(\sigma\) as the function in the function class that can best fit each \(h(x_i)\) to the labels \(\sigma_i\) such that the sum is maximized. In other words, it is the capacity of the function class in fitting the data to random labels.
Trivially, a Rademacher complexity of 1 given the \(n\) datapoints means the function class is large enough to fit all random labelings.
-
Uniform stability: uniform stability captures the notion that the predictions of a classifier does not change too much when only a single example is removed or perturbed. A classifier \(f\) is \(\beta\)-uniformly stable with respect to some loss \(\ell\) if for any two datasets \(S, S'\) that only differ in a training example, then the difference in their losses is bounded by \(\beta\) for any input-label pair \((x,y)\), we have:
\[|\ell(f_S(x), y) - \ell(f_{S'}(x), y)| < \beta,\]where \(f_S\) and \(f_{S'}\) are the classifier trained on \(S\) and \(S'\) respectively.
The authors found that standard neural network architectures like Inception V3 on popular benchmark datasets like CIFAR10 could fit random assignment of training labels, and also other forms of corruption of the data:
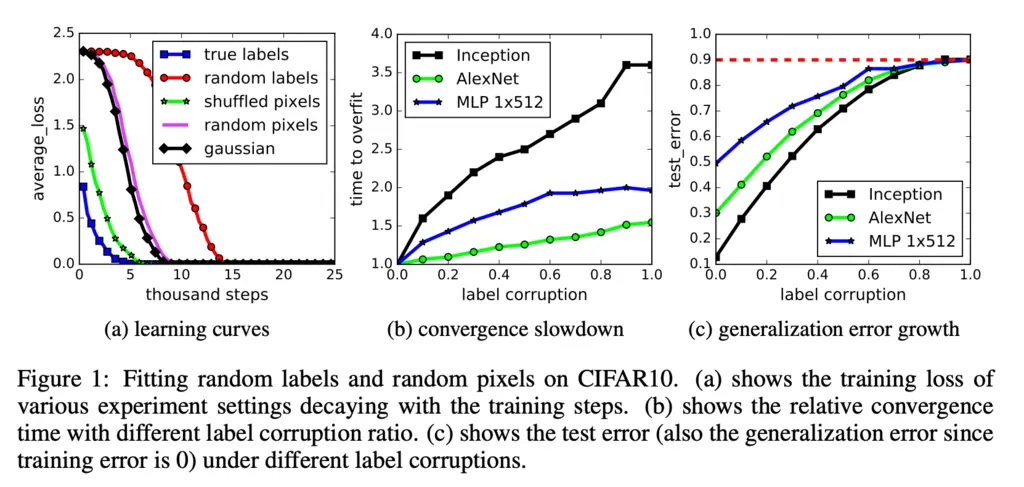
This shows that the VC dimension of the network is probably larger than the dataset, and that the Rademacher complexity is close to one. If their complexities are so large then any theory based on it to show some regularization property to help in demonstrating how it generalizes is essentially useless.
Hence, alternative frameworks for thinking about generalization for large networks beyond standard learning theory concepts are required.
2. Explicit Regularization Helps, But Is Not Necessary For Generalization
Since implicit regularization (if any) of the networks was clearly not enough to restrict its expressiveness to fit any random data, what if we introduced explicit regularization such as dropout, weight-decay, and batchnorm?
Unfortunately, even with regularization the various popular architectures were still able to almost perfectly fit random labels:
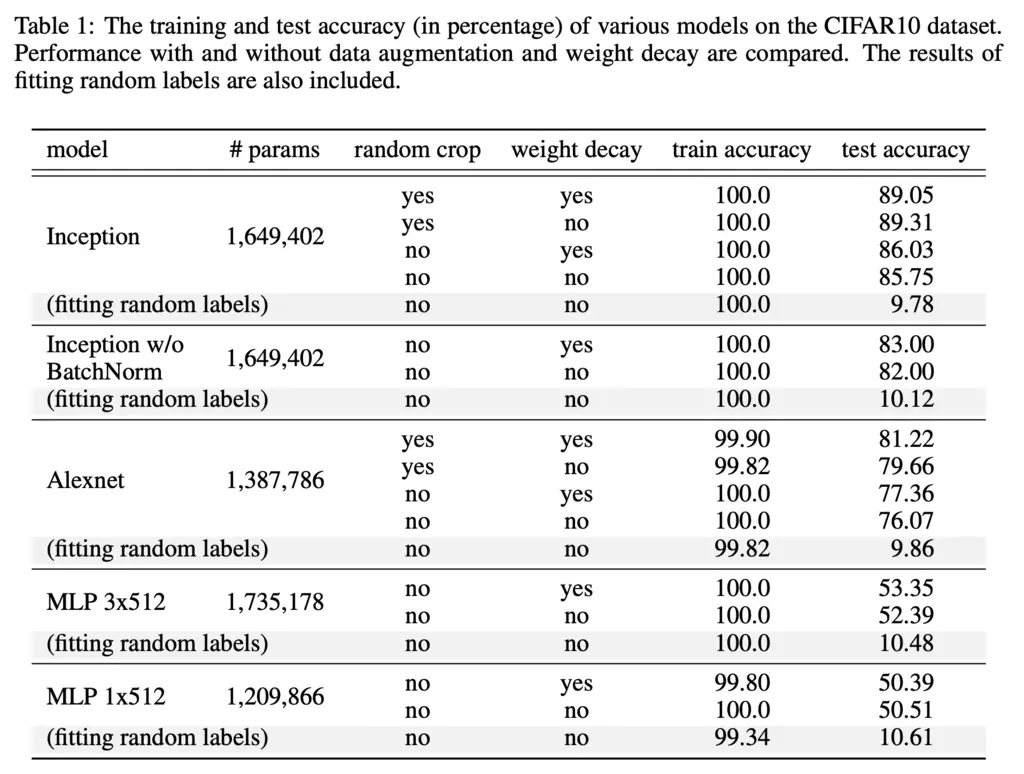
Note that since CIFAR10 has 10 classes, random guessing gives 10% accuracy and hence fitting random labels predictably performed no better than random guessing.
In addition, even in the absence of any explicit regularization, it could also generalize well and have test accuracy almost on-par to when explicit regularization was enabled.
This shows that explicit regularization can help, but is not essential for generalization.
3. Finite-Sample Expressivity
The fact that all our popular neural networks can memorize training labels perfectly might feel a bit shocking or even depressing.
It might then be worth asking just how big (or small) a neural network must be before it is capable of such memorizing.
Traditionally, people answered this by attempting to find the function class that a neural network with a certain number of parameters can express. However, the authors take a different and much simpler approach by asking instead how large a neural network must be to memorize \(n\) samples. This led to their main theoretical result in the paper:
Most Glaring Deficiency
In all honesty, I thought this was a very interesting and well-written paper considering the first author did it while interning at Google Brain (in contrast I feel that I accomplished nothing as cool or novel during my own internships).
However, I must say that I would be surprised if no one realized that neural networks are capable of fitting random labels before this paper. I’m very positive that by the way of a programming bug or otherwise, someone should have already discovered this phenomenon way before, but probably did not think a lot about the ramifications of this fact.
In addition, it might have been interesting to explore how removing known inductive bias that helps a particular problem domain may affect generalization. For instance, instead of using CNNs with strong inductive bias for visual data, it may have been interesting to see how the results would change if regular neural networks were used instead.
Conclusions for Future Work
Understanding generalization of over-parameterized models requires us to go beyond classical learning theory and explore alternative ways of studying the models, since these models are so over-parameterized and expressive that these theories would only ever be able to produce trivial bounds.