Three Important Things
1. Wide Two-Layer Neural Networks with Gram Matrix Spectral Properties Enjoys Linear Convergence Rate
This paper shows theoretically how overparameterization of a two-layer neural network can result in a linear rate of convergence (linear when logarithms are taken, hence it really converges exponentially fast).
The setup of the paper is a standard two-layer neural network of the following form:
\[f(\mathbf{W}, \mathbf{a}, \mathbf{x})=\frac{1}{\sqrt{m}} \sum_{r=1}^{m} a_{r} \sigma\left(\mathbf{w}_{r}^{\top} \mathbf{x}\right)\]The first layer is initialized with random Gaussians, and the second layer is initialized uniformly with either -1 or +1. The reason \(\pm 1\) initialization was used in the second layer is because it simplifies the Gram matrix of the weights.
The Gram matrix \(\bH\) referred to in the paper is defined as the matrix product of the differential map of \(f\) with its transpose, i.e \(\nabla_W f \, \nabla_W f^{\top}\). This is similar to the kernel in the neural tangent kernel paper. Note that the eigenvalues of the Gram matrix are always non-negative since the Gram matrix is positive semi-definite.
The main result of the paper states that if the following conditions hold:
- The neural network is initialized in the manner mentioned previously,
- The Gram matrix \(\bH\) induced by ReLU activation and random initialization has its smallest eigenvalue \(\lambda_0\) bounded away from 0 (this is the key assumption used),
- We set step size \(\eta = O \left( \frac{\lambda_0}{n^2} \right)\),
- The number of hidden notes is at least \(m = \Omega \left( \frac{n^6}{ \lambda_0^4 \delta^3 } \right)\),
then with probability at least \(1-\delta\) over the random initializations, we have that for any time step \(k\), the difference between the output of the network \(\bu(k)\) and the labels \(\by\) can be bounded:
\[\| \bu(k) - \by \|_2^2 \leq \left( 1 - \frac{\eta \lambda_0}{2} \right)^k \| \bu(0) - \by \|_2^2.\]In other words, it converges at a linear rate.
2. Spectral Norm of Gram Matrix Does Not Change Much During Gradient Descent
An essential part of the proof in the main theorem requires that the smallest eigenvalue assumption of the Gram matrix \(\bH\) holds throughout gradient descent. They showed this by first showing that the randomly initialized \(\bH(0)\) at time step 0 is close in spectral norm to \(\bH^{\infty}\), defined as
\[\mathbf{H}_{i j}^{\infty}= \mathbb{E}_{\mathbf{w} \sim N(\mathbf{0}, \mathbf{I})}\left[\mathbf{x}_{i}^{\top} \mathbf{x}_{j} \mathbb{I}\left\{\mathbf{w}^{\top} \mathbf{x}_{i} \geq 0, \mathbf{w}^{\top} \mathbf{x}_{j} \geq 0\right\}\right].\]Precisely, they showed that if \(m\) is wide enough, then with high probability,
\[\left\|\mathbf{H}(0)-\mathbf{H}^{\infty}\right\|_{2} \leq \frac{\lambda_{0}}{4}\]and \(\lambda_{\min }(\mathbf{H}(0)) \geq \frac{3}{4} \lambda_{0}\).
They then used this result to show that any \(\bH(t)\) is stable, and is close to its value at initialization.
3. Synthetic Data To Validate Theoretical Findings
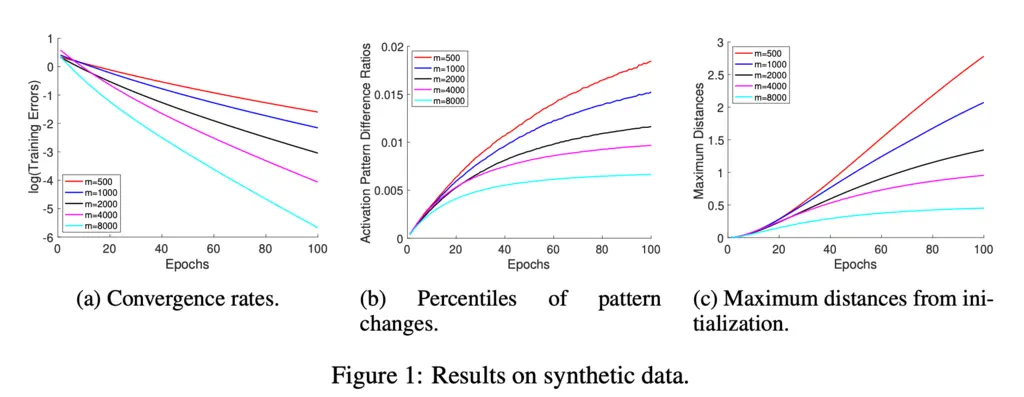
The authors generated synthetic data to verify their theoretical findings. They found that:
- Greater widths result in faster convergence,
- Greater widths result in fewer activation pattern changes, which verifies the stability of the Gram matrix,
- Greater widths result in smaller weight changes.
Most Glaring Deficiency
The assumption that the second layer of the neural networks is initialized with \(\pm 1\) values feels quite unrealistic, although it is admittedly to simplify the theoretical analysis. It would be interesting to see if such an initialization pattern could actually be competitive with established weight initialization techniques in practice.
Conclusions for Future Work
Their work provides a further stepping stone to understanding why over-parameterized models perform so well. As the authors mentioned, it may be possible to generalize the results of their approach to deeper neural networks.