Three Important Things
1. Training Data Extraction Attack
In this paper, the authors come up with and investigate the efficacy of a training data extraction attack on large language models. To mitigate the potential harms of the study, they performed this on GPT-2, where both the training dataset and models are already public. They used the largest GPT-2 model with 1.5 billion parameters.
An example of personally identifiable information that they managed to extract is given below (with permission from the individual affected):
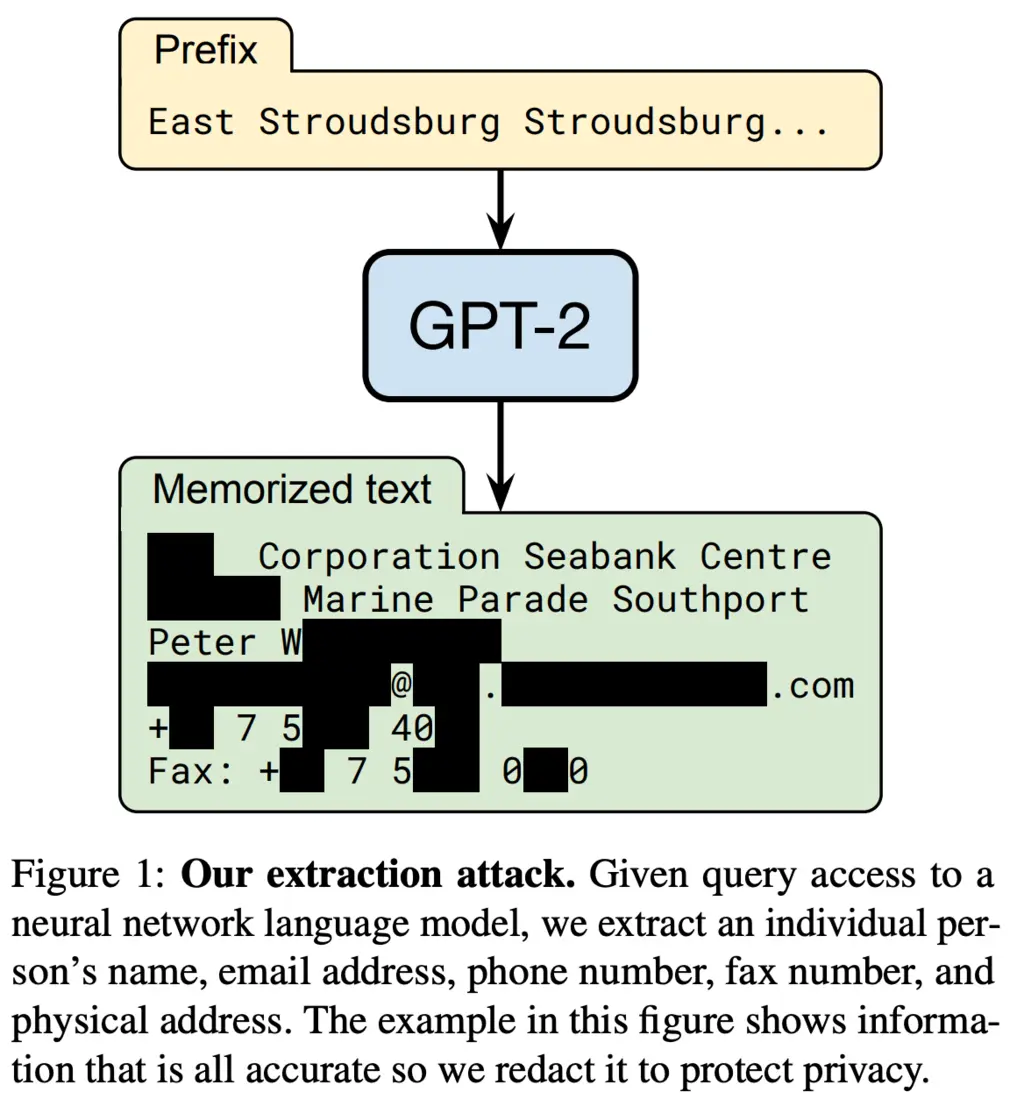
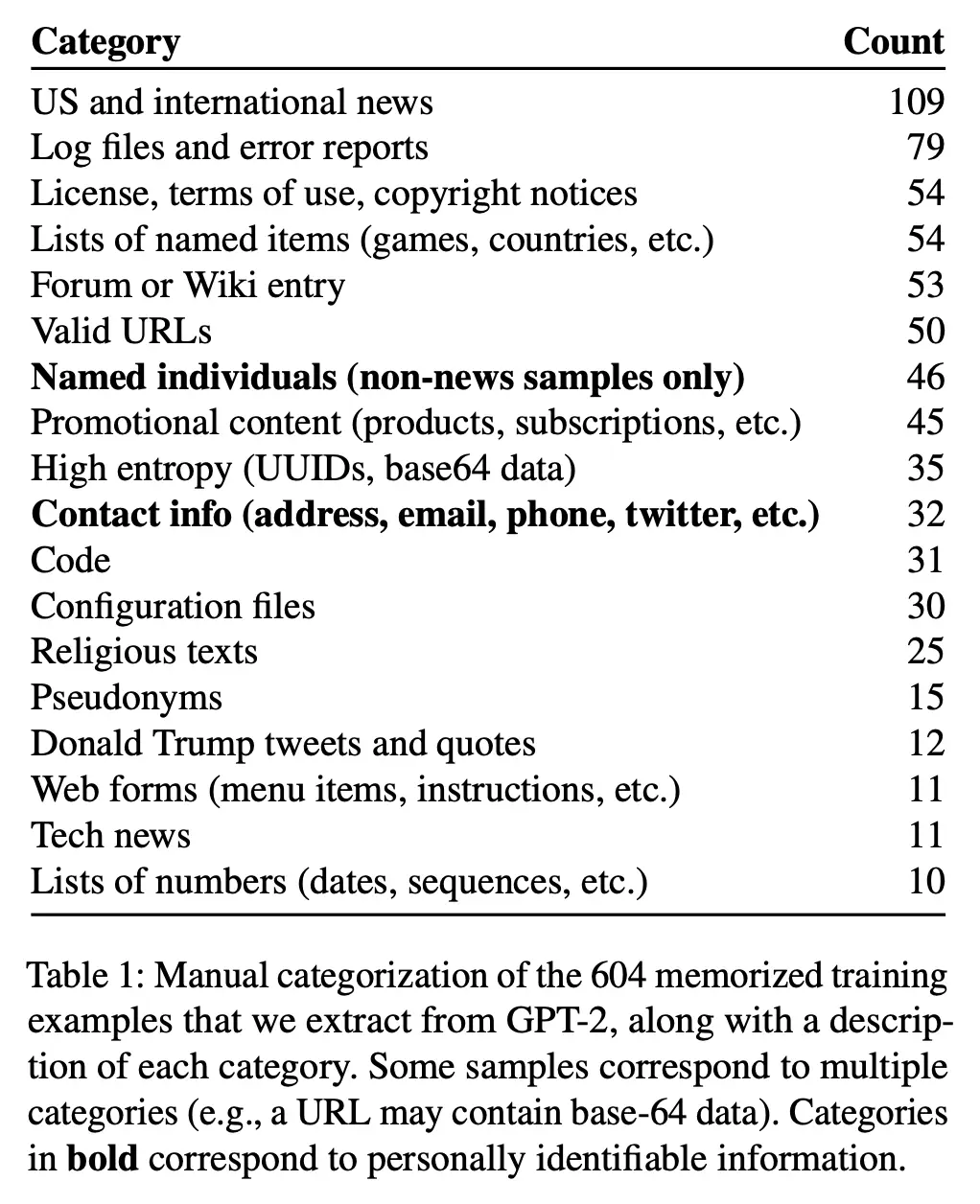
The table below shows the types of memorized content that they were able to recover:
Since it is possible that many common text phrases will be memorized by the language model (such as the MIT license), the authors are concerned only about uncovering eidetic memorization. This is data that is memorized despite only appearing a very small number of times.
Formally, they define \(k\)-eidetic memorization for a string \(s\) as being able to recover \(s\) from the language model using a “reasonable” prompt, when it only appears at most \(k\) times in the training dataset. There is some nuance here about whether a prompt is reasonable as there are pathological corner cases where you could simply ask the prompt to repeat a string back to you. This was not mentioned in the paper, but I believe a reasonable working definition could be that there is information gain (in a Shannon entropy manner) when I see the result, conditioned on the prompt.
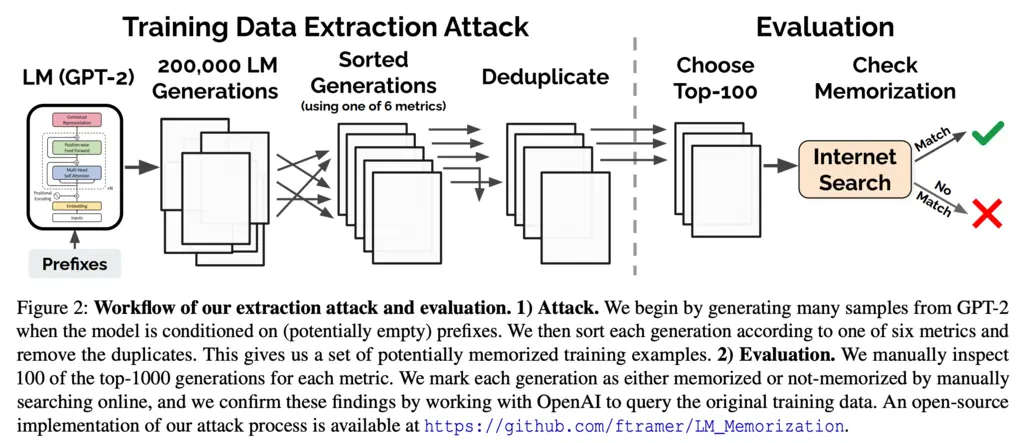
The high-level workflow of their attack is as follows.
- They provide prompts (potentially just the empty start-of-sentence token) to the GPT-2 language model, and auto-regressively sample from it
- Use one of 6 metrics to determine the likelihood that each of the generations contains memorized content. These will be discussed later.
- The generated texts are de-duplicated
- The top 100 generations (according to the metric) are chosen
- The researchers manually verified whether the generations are indeed memorized by an internet search, with confirmation with OpenAI (who developed GPT-2)
2. Text Generation Schemes
The authors initially faced the problem of having a low diversity of outputs when just performing top-\(n\) sampling autoregressively on an empty prompt. To increase the precision and recall of generated text that corresponds to eidetic memorization, they found two techniques that helped:
-
Sampling with a Decaying Temperature: Borrowing ideas from simulated tempering, they initially start sampling with a higher temperature which then decays throughout the generation process. Decaying the temperature is necessary to eventually extract high-confidence sequences.
-
Conditioning on Internet text: The authors curated a dataset that was a cleaned subset of the Common Crawl, and used short samples from this dataset as prompts. They found that using Internet-sourced text as prompts helped to elicit a larger diversity of responses from GPT-2, which was also trained on Internet data.
3. Membership Inference
After generating 200,000 samples, it is very much infeasible to try to evaluate them all by hand to determine whether they were memorized, and hence the authors used different heuristics as metrics to determine the likelihood that a piece of generated sample was eidetically memorized.
- Comparing to other neural language models: they compared the perplexity of the output from the largest 1.5 billion GPT-2 XL model against its smaller counterparts: Small (117M parameters) and Medium (345M parameters). If a piece of output was not surprising to the XL model but was surprising to either the Small or Medium model, then it likely indicates that the output was \(k\)-eidetic memorized and is not a product of general natural language.
- Comparing to zlib compression: a common failure mode was the propensity for the text to spit out repetitive text which has low perplexity, despite this being very unnatural in real life, such as the repeated text “I love you. I love you. I love you…”. To catch this case, the authors applied
zlibcompression on the output, and used the ratio of perplexity tozlibcompression entropy as a metric. - Comparing to lowercased text: they measured the perplexity of both the original output, and when it is completely lowercased. If the lowercased output has much higher perplexity (indicating the casing was important), then it hints that it was likely memorized.
- Perplexity on sliding window: In some cases only a part of the output has low perplexity and contains memorized text, while other parts could have low likelihood. This is especially so if simulated tempering was used. As such, the minimum perplexity averaged over a sliding window of 50 tokens was used.
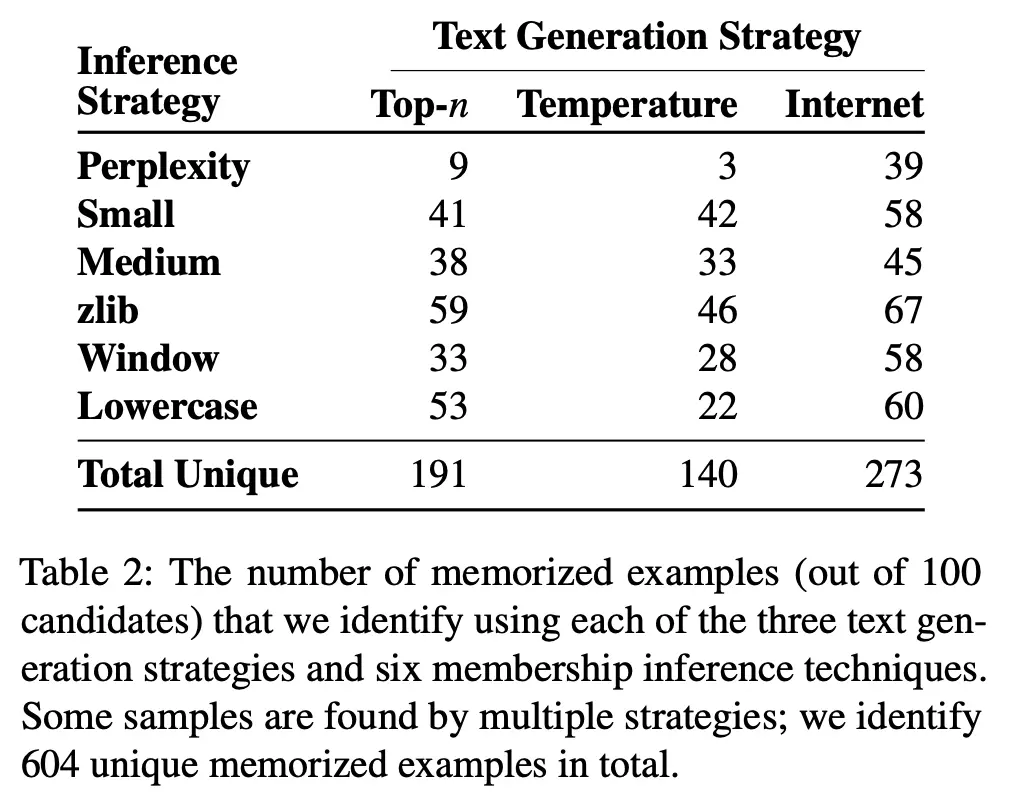
The number of memorized samples recovered using each of these metrics and text generation strategies are given below:
Most Glaring Deficiency
The different metrics for membership inference are orthogonal in some sense that they each have different strengths. I feel that the authors could have experimented with combining the metrics, weighted in some appropriate manner, to obtain even higher rates of recovering eidetically memorized content.
Conclusions for Future Work
The results of this paper are an understatement of the true extent to which training data can be recovered from black-box querying of large language models. As models get larger, this is only going to become an even bigger issue.
This also shows that concerns from companies using foundation models for their internal use about not having their confidential data trained on are extremely valid, and per-organization fine-tuned models to avoid information leakage may be fundamentally unavoidable unless there is a way to train in a privacy-preserving manner without incurring a huge computational tax.