Three Important Things
The authors state that the goal of the paper is not to introduce any novel ideas, but rather to push the limits of the current known architecture and see what results can be achieved.
1. Text-to-Text Transfer Transformer (T5)
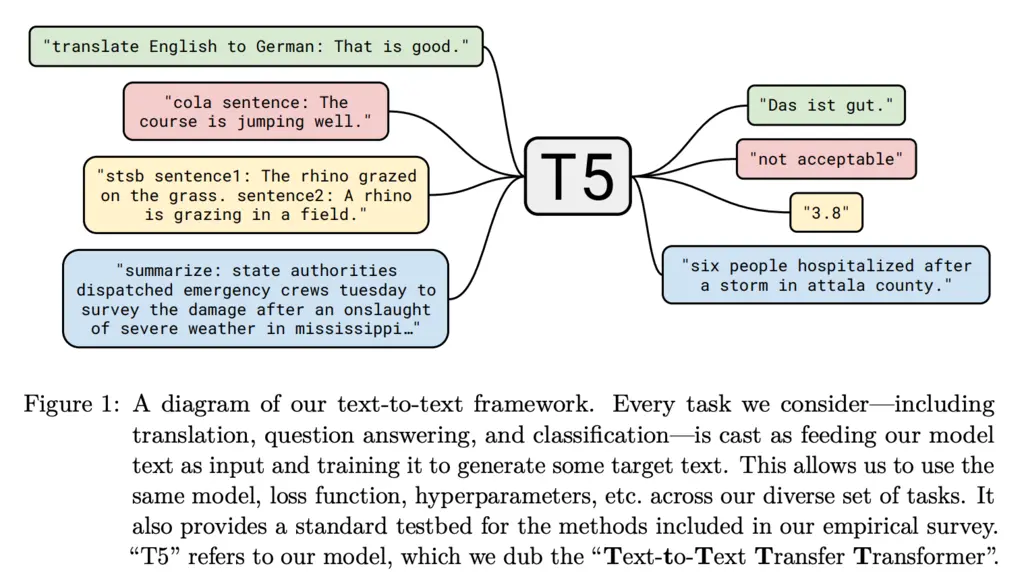
The Text-to-Text Transfer Transformer (T5) model has an encoder-decoder architecture. The author takes the view that all problems can be viewed as a text-to-text problem, and therefore this architecture can generalize to all NLP tasks.
The encoder has a “fully-visible” attention mask, meaning that the attention mechanism can attend to any position in the input. On the other hand, the decoder has a “causal” attention mask, and can only attend to tokens \(j < i\) when it is trying to compute the token at position \(i\), to prevent it from seeing the future inputs which would otherwise trivialize the training process.
The decoder produces the output in an autoregressive manner, meaning that it produces one output token at a time, and then concatenates this output to the input and repeats the process until the end of sequence token is output.
2. Prefix LM
While the best-performing T5 variant has an encoder-decoder architecture (which is the standard architecture T5 would refer to), the authors also experimented with and performed comparisons against the language model and prefix LM architectures.
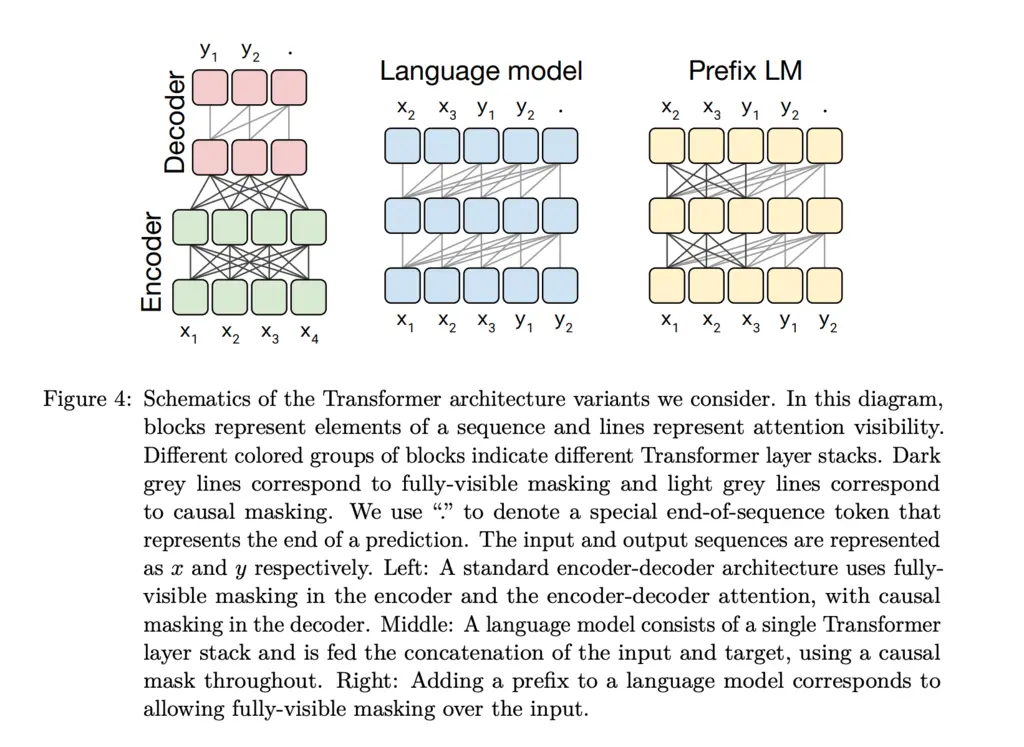
The goal of the language model architecture is to predict token \(i+1\), given all tokens up to \(i\). A major downside of this is that the model’s representation of the \(j\)th entry of the input can only depend on all tokens less than \(j\).
However, for text-to-text tasks, it could be possible that there is a lot of useful context on the right of \(j\) which is still in the input prompt that is relevant. For instance, for English to German translation, if the input prompt is translate English to German: That is good. target: , then it makes sense for the tokens at the start to also be able to attend to future tokens in the prompt.
The prefix LM architecture addresses this limitation by allowing for fully-visible masking in the prefix portion of the input, and therefore the representation of all tokens can attend to every other token in the input.
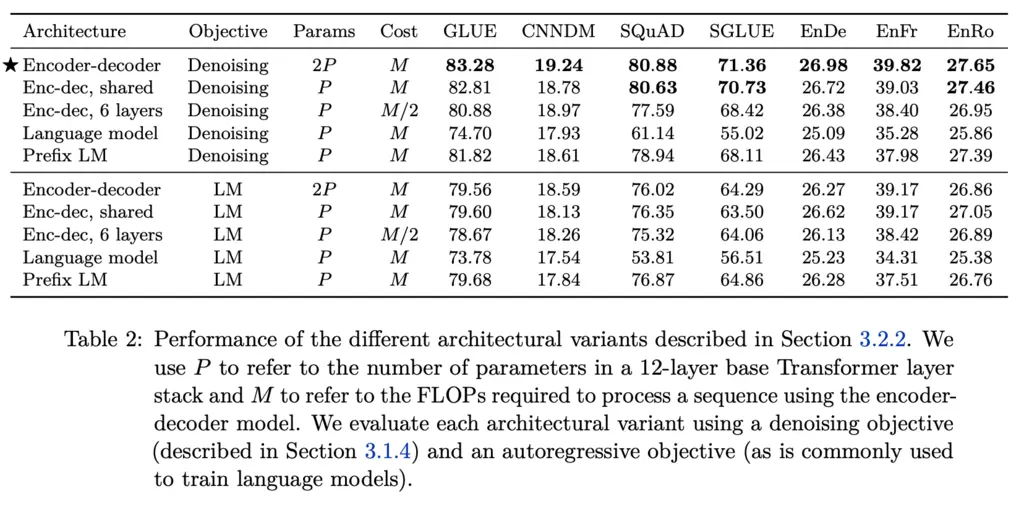
The following table shows the results of comparisons between the three architectures, with the encoder-decoder performing the best, and the language model the worst.
3. Colossal Clean Crawled Corpus
The Common Crawl is a dataset of text data scraped from the web, with around 20TB of data extracted each month. However, most of the text scraped is not natural language, and is instead web boilerplate code, error messages, gibberish, etc.
The authors cleaned up the Common Crawl to obtain the Colossal Clean Crawled Corpus (C4), by using the following heuristics:
- Keeping only text terminated by punctuation
- Discard pages with < 5 sentences
- Keeping lines with at least 3 words
- Discarding pages with offensive words
- Removing any lines containing the word Javascript
- Discarding any pages with “lorem ipsum” text
- Removing pages containing a curly bracket
{, as it usually indicates code - Deduplicating the data by removing any three-sentence span that occurs in the dataset more than once, to just having it show up once
The T5 transformer was then trained on C4 for \(2^{19} = 524,288\) steps with a max sequence length of 512, and a batch size of 128 sequences.
Most Glaring Deficiency
The method used to clean the C4 corpus feels somewhat arbitrary and perhaps still very much incomplete. Due to the importance of data in the performance of the model, it would have also been helpful to have trained on the Common Crawl as well to perform an ablation study on whether C4 resulted in better performance.
Conclusions for Future Work
The text-to-text approach for modeling language tasks is a promising avenue to generalize task-specific architectures, and could become a future default approach due to its simplicity and generalizability.
The authors also found that pushing the limits of the architecture by a very large 11-billion parameter model resulted in state-of-the-art performance across many tasks, showing that scale can result in performance gains.