Three Important Things
1. Generative Pre-Training
The authors introduce a paradigm for language models where it undergoes unsupervised generative pre-training on a large corpus of unlabeled data, before undergoing fine-tuning on supervised data for a specific task. They show that language pre-training results in significant performance gains on various NLP tasks.
2. Traversal-Style Architecture for Different NLP Tasks
Different NLP tasks have different input-output structure formats. For instance, while classification takes in the text to classify as input, and outputs the predicted class, other tasks like multiple choice could contain a single context and multiple answers to choose from.
To avoid having to retrain them for different tasks, the authors came up with a traversal-style approach such that the same pre-trained Transformer model can be applied to all of them, given in the figure below.
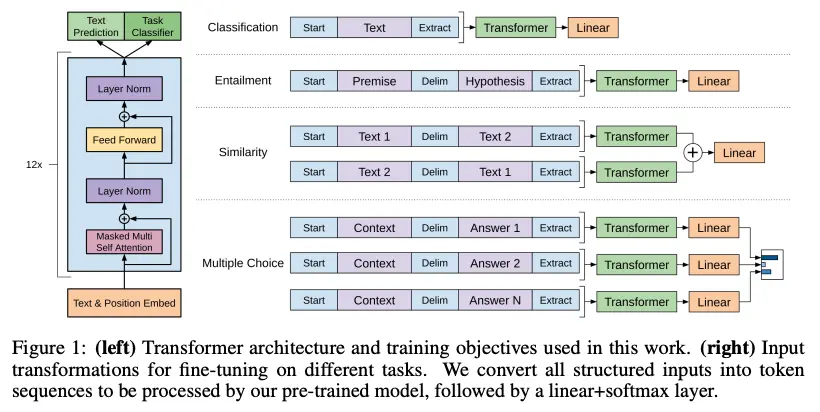
3. Including Language Modeling as an Auxiliary Objective to Fine-Tuning
During the unsupervised pre-training step, the following log-likelihood objective is maximized:
\[L*1(\mathcal{U}) = \sum_i \log P(u_i \mid u*{i-k}, \cdots, u\_{i-1}; \Theta),\]where
- \(\mathcal{U} = \{ u_1, \cdots, u_n \}\) are the input tokens,
- \(\Theta\) are the parameters for the neural network,
- \(P\) is the probability.
Next, during the supervised fine-tuning step, traditionally only the log-likelihood of the supervised labels given the inputs is maximized:
\[L_2 (\mathcal{C}) = \sum_{(x,y)} \log P(y \mid x^1, \cdots, x^m),\]where
- \(x^1, \cdots, x^m\) are the input tokens,
- \(y\) is the label.
However, the authors experimented with also adding \(L_1(\mathcal{C})\), the objective from the unsupervised pre-training step as an auxiliary objective, multiplied by some scaling factor \(\lambda\) to obtain the following final loss function:
\[L_3(\mathcal{C}) = L_2(\mathcal{C}) + \lambda \times L_1(\mathcal{C}).\]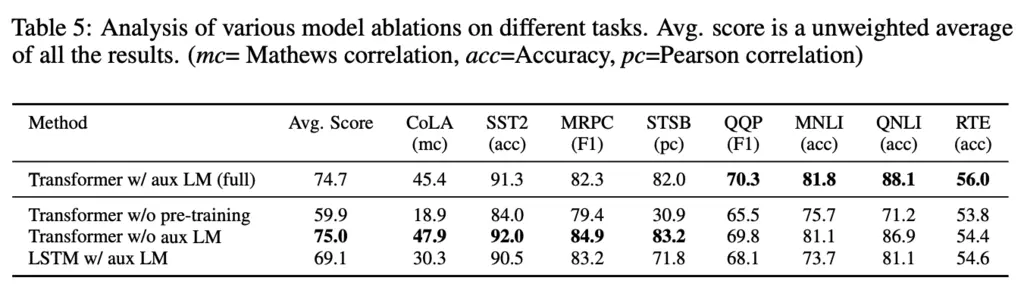
An ablation study of the inclusion of the auxiliary objective (ie the \(\lambda \times L_1(\mathcal{C})\) term) is given in the table above. The authors note that the auxiliary objective helps with performance on larger datasets, but harms for smaller datasets.
Most Glaring Deficiency
Could have also performed an analysis on the effect of varying the size of the pre-training corpus (in addition to pre-training updates), on the final result of the final fine-tuned NLP tasks.
Conclusions for Future Work
The paper introduced a useful generative pre-training paradigm that is now standard for many LLM applications.