Three Important Things
1. WebText
Web scrapes like the Common Crawl suffer from many data quality issues, and also likely contain data used in the test set of various NLP evaluation tasks. Due to the difficulty of data filtering, the authors created a new dataset called WebText that scraped the content from all outbound links from Reddit, which acts as a filter for content that may be interesting to humans.
They did not follow Wikipedia links to avoid overlaps with the Wikitext dataset.
2. Byte Pair Encoding (BPE)
Many other language models at the time performed extensive pre-processing on the input, such as lower-casing and tokenization. This restricts the generality of the output that it can produce.
On the other extreme, a possible approach is to use byte-level encoding, which allows the full range of UTF-8 bytes to be captured. However, this performed worse in practice than word-level embeddings, a behavior that was also replicated in the author’s experiments.
Instead, the authors use byte pair encoding (BPE), which starts with byte-level encodings before merging the more common byte pairs into a single token. A good explanation of BPE is given in this HuggingFace tutorial.
The authors modified BPE such that instead of greedily merging characters that could result in sub-optimal tokens, they prevent merges across character categories, with the exception of spaces.
3. Overlaps between Training and Test Data
The authors noted that the increasing sizes of the web crawls used for training large language models are directly responsible for small incremental sizes in improvements, due to overlaps between the crawled data and the test set.
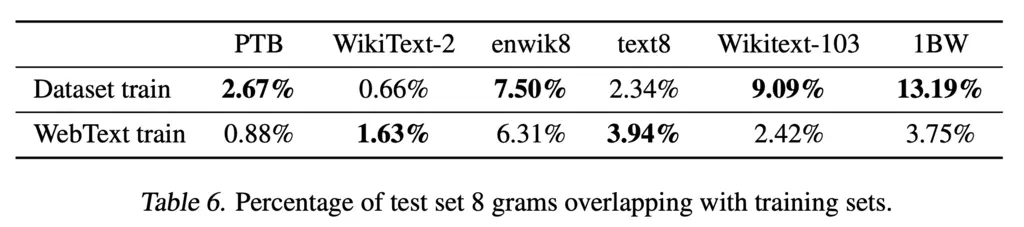
To investigate this further, they constructed a Bloom filter using 8-grams and sought to find overlaps between the test and training sets. The worst culprit that they found was 1BW, which has a 13.2% overlap between its train and test set.
Most Glaring Deficiency
There still exist significant overlaps between the WebText train and test data. It is worth attempting to de-duplicate such overlaps by removing passages that appear in the test set from the train set, though this would require a much more complicated hashing scheme than Bloom filters, which is not capable of identifying the source of collisions. However, this would still be very valuable to the ML research community by having a more objective and accurate standard.
Conclusions for Future Work
Be aware of unintentional information leaks from training to test data. This is becoming increasingly unavoidable due to the increasing scale of training data that is scraped, and hence one should be wary about the source of minute performance gains with respect to the training set used.