Three Important Things
1. Chain-of-Thought Prompting for Large Language Models
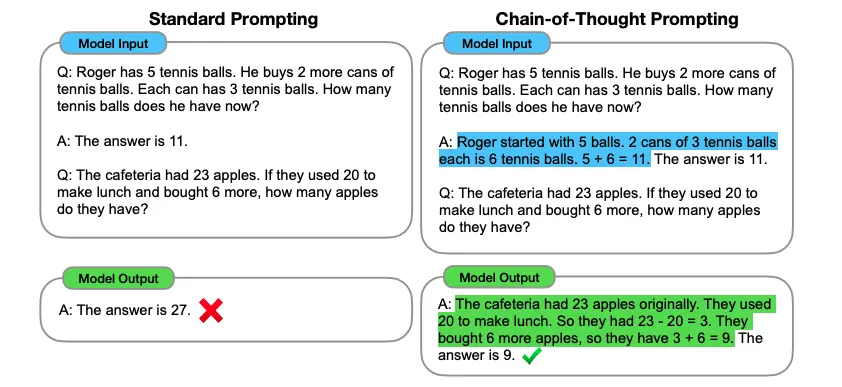
Chain-of-thought prompting is a few-shot prompting technique where exemplars provided include reasoning steps on how the answer is arrived at. This results in a significant improvement for large language models in multi-step reasoning tasks like arithmetic questions. It is robust to differences in the prompting style.
2. Emergent Property of Large Language Models
The success of chain-of-thought prompting is an emergent property of large language models, but on the contrary could hurt performance for smaller models as compared to standard prompting. It is an interesting future direction to understand how this technique also be adapted to smaller models.
3. Why Chain-of-Thought Prompting Works
Ablation studies were performed to understand how chain-of-thought prompting works, and if there are other techniques to replicate the results.
This included:
- Verbalizing mathematical equations related to the problem,
- Spending extra dummy tokens equivalent to the difficulty of the problem to obtain more intermediate tokens for computation,
- Adding reasoning steps after the answer, under the suspicion that the reasoning prompt helps to access relevant knowledge.
All of them performed only near baseline levels, indicating that there may be something unique to chain-of-thought prompting.
Most Glaring Deficiency
Visualizing the attention maps may be able to provide some insights into the inner workings of chain-of-thought prompting, but was not performed.
Conclusions for Future Work
While generalized abstract multi-step reasoning and planning is currently still out of our reach, we can try to break down the task as much as possible using techniques like chain-of-thought prompting as an intermediate step.
Furthermore, it will also be interesting to further understand how this chain-of-thought property emerges as a result of larger language model sizes, to allow us to understand how further reasoning capabilities can be developed.