Three Important Things
1. A New Taxonomy For Multimodal Machine Learning Research
The authors propose a new taxonomy for classifying multimodal machine learning research, categorized into 6 different categories given below:
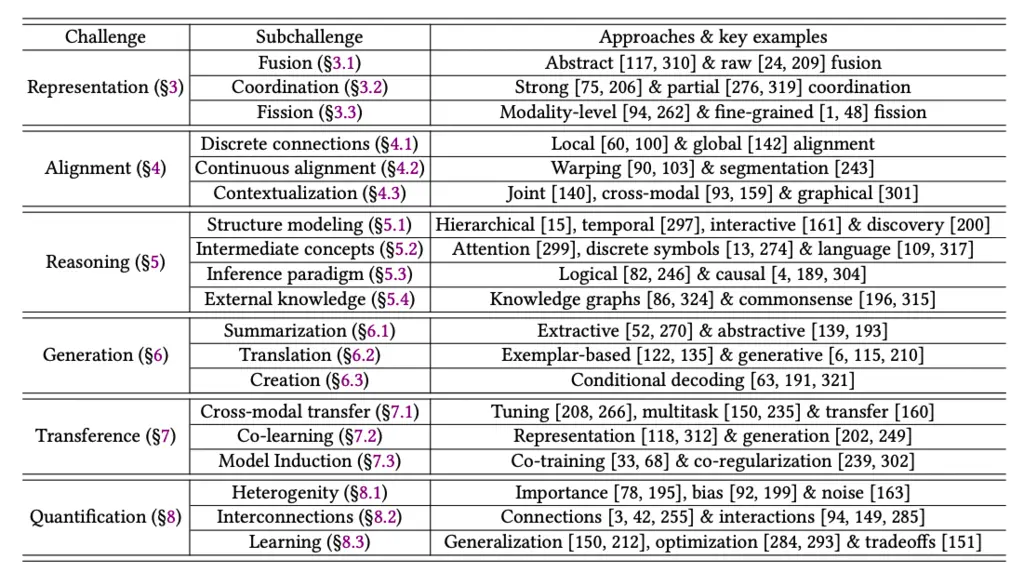
- Representation: What representations to use to best learn from multi-modal inputs?
- Alignment: Capturing relationships between inputs from different modalities
- Reasoning: Inference on multi-modal data over multiple steps
- Generation: Generating new outputs of a particular modality
- Transference: Allowing different modalities to learn from each other
- Quantification: An empirical and theoretical approach to multimodal models by quantifying their information content and exploring the extent and presence of relationships between multimodal data
2. Contrastive Learning
Contrastive learning, which is where similar samples are encouraged to be closer in the representation space and dissimilar samples are pushed further apart, is a popular approach for learning interactions between multi-modal inputs.
3. Attention Maps for Intermediate Concepts
When performing multi-step reasoning on multimodal data, attention maps are a popular choice as it is human-interpretable and sufficiently general.
Most Glaring Deficiency
It’s rather hard to criticize a survey, but some questions I had were whether the authors were aware of any research directions that don’t fit anywhere in the taxonomy, or perhaps span several categories.
It would have also been illuminating to include specific examples for the more abstract research questions for people like me who are less familiar with work in the space.
Conclusions for Future Work
It might be helpful to see where work on multimodal machine learning falls in the taxonomy, to understand which dimension of the problem it is tackling, and what are the other dimensions left to view the problem in. Perhaps the same technique could be applicable across several of the challenge domains.